Hello,
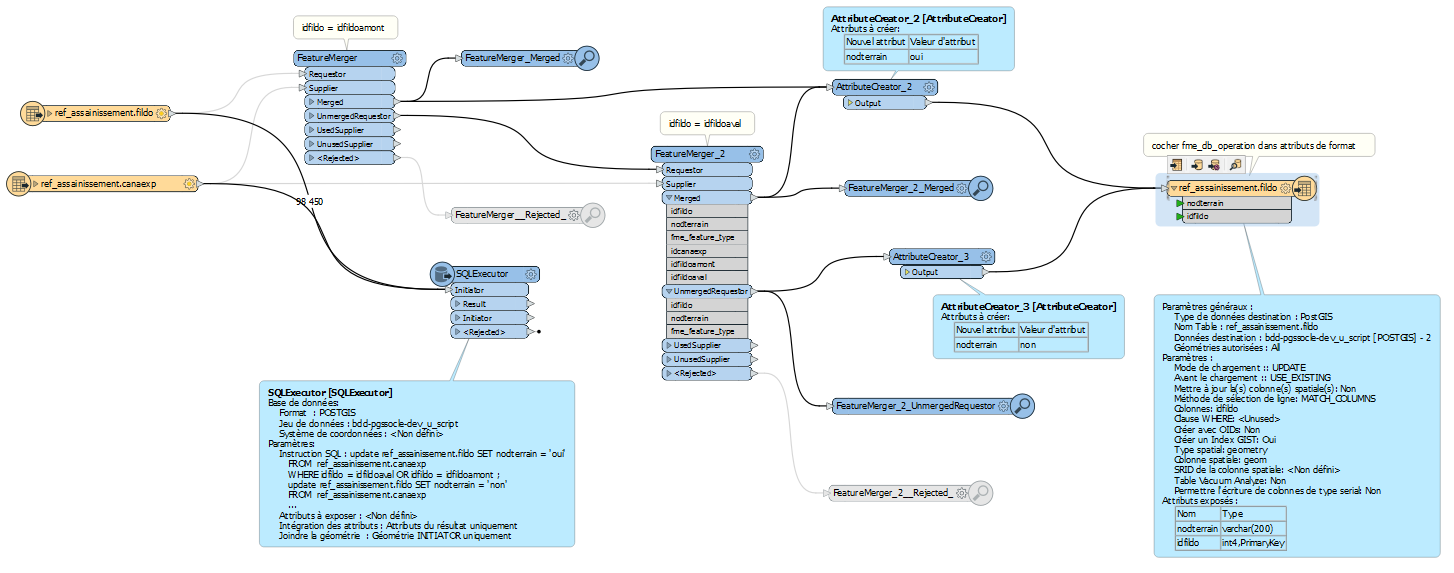
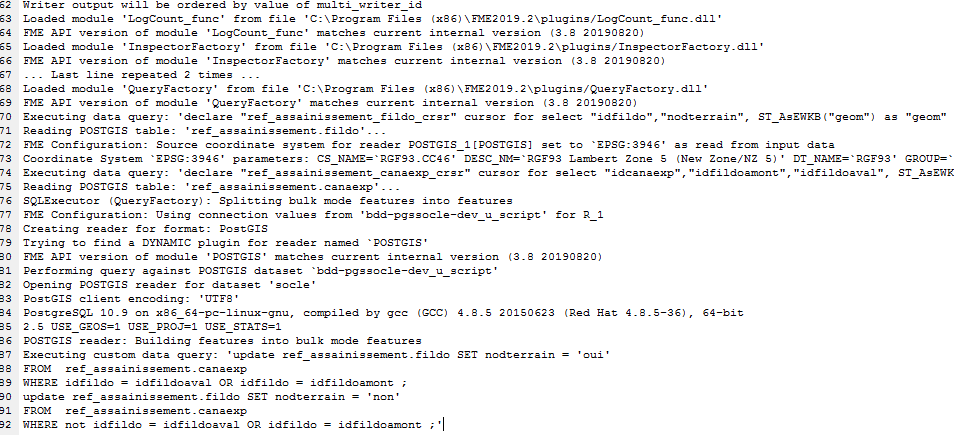
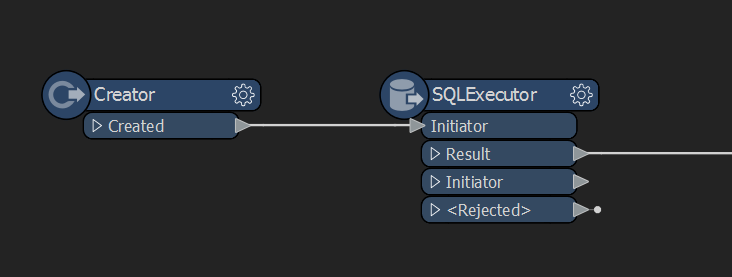
I'm using a SQL Executor transformer in my workspace. It is very very very slow (10 features in 10 minutes, I have 200 000 features to read).
I have 2 readers and 1 writer from PostgreSQL spatial tables. I created indexes in geom attribute (gist) and primary key (btree) for the 2 readers.
The SQL script is :
update ref_assainissement.fildo SET nodterrain = 't'
FROM ref_assainissement.canaexp
WHERE idfildo = idfildoaval OR idfildo = idfildoamont
(so very simple)
Any idea ?
Thank you !