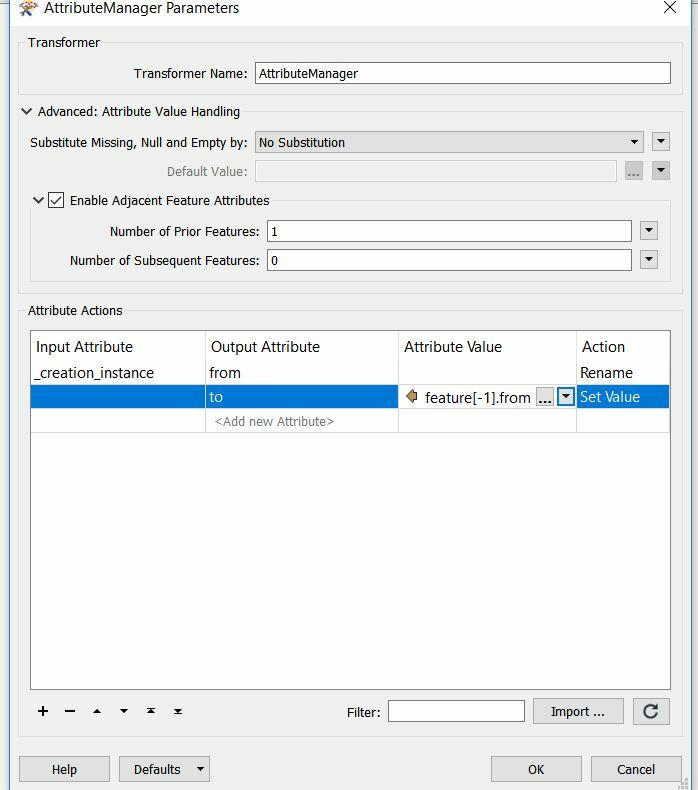
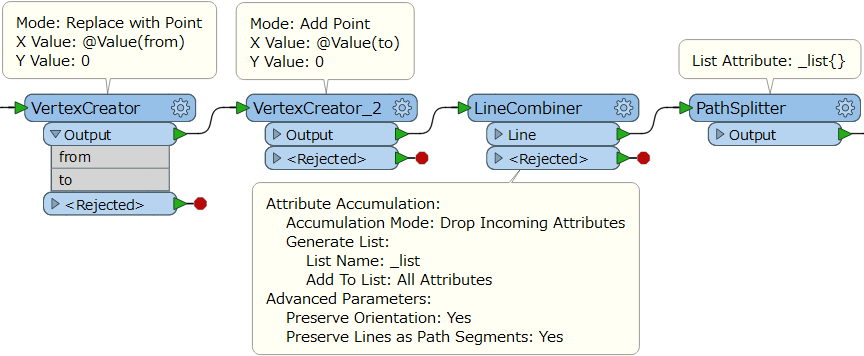
I have some features with attributes as follows
fromto41444146412441815406700241214124700299663418141449966399661540675406414654067
And I'm aiming to reprder/assign an ordered value so that the from value equals the to value of the preceding feature.
fromto41214124412441814181414441444146414654067540675406540670027002996639966399661
All suggestions appreciated.