Hi all,
FME beginner here.
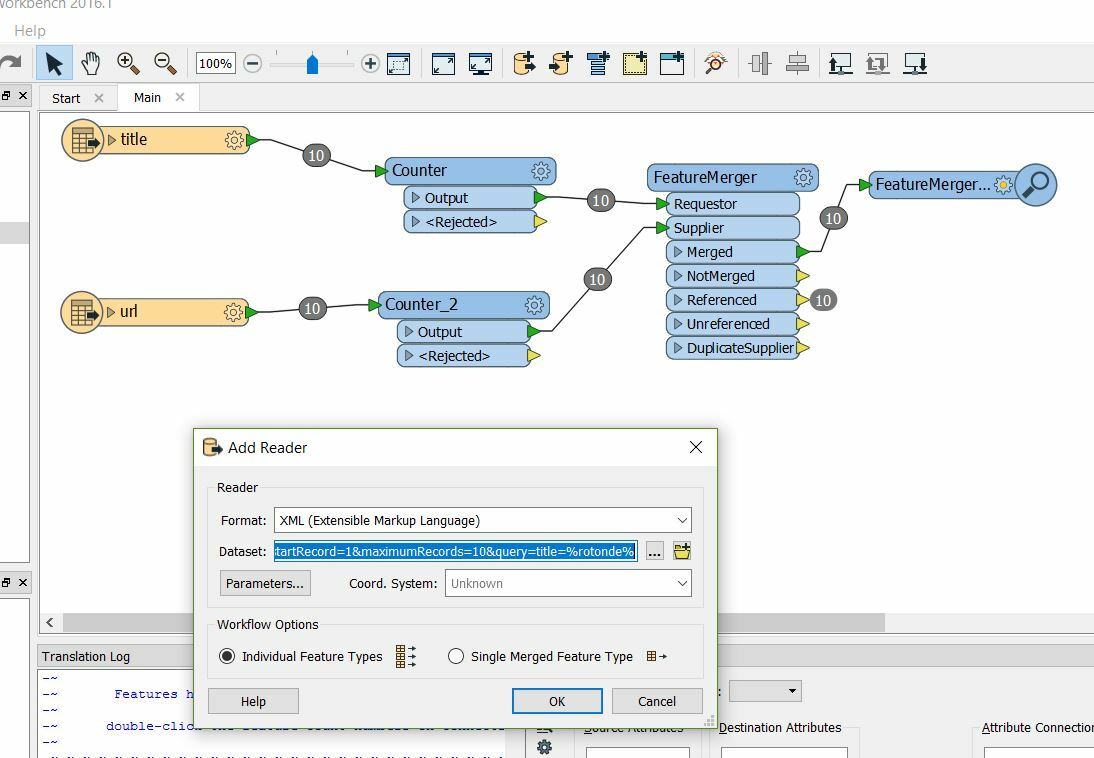
I'm trying to process data from a Dutch government website.
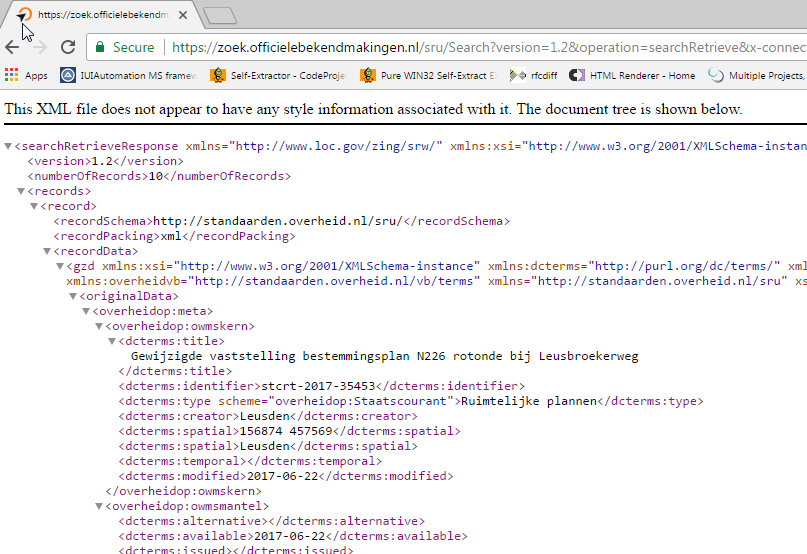
One can request data using search keys in the URL (SRU I believe?) - the response is an XML.
e.g.
I'm trying to put in multiple search strings and process the results / output in FME.
What I have now:
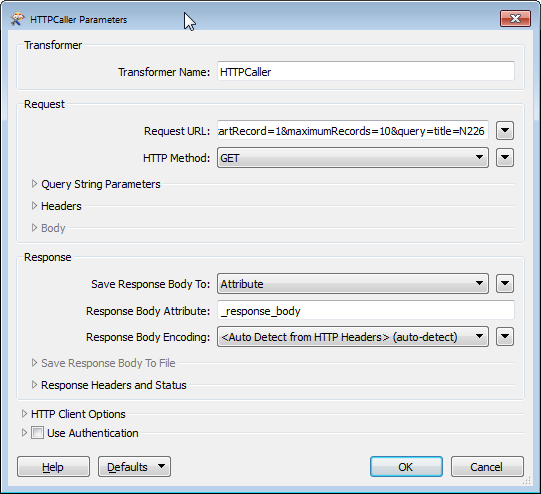
Excel file with search strings connected to HTTPCaller.
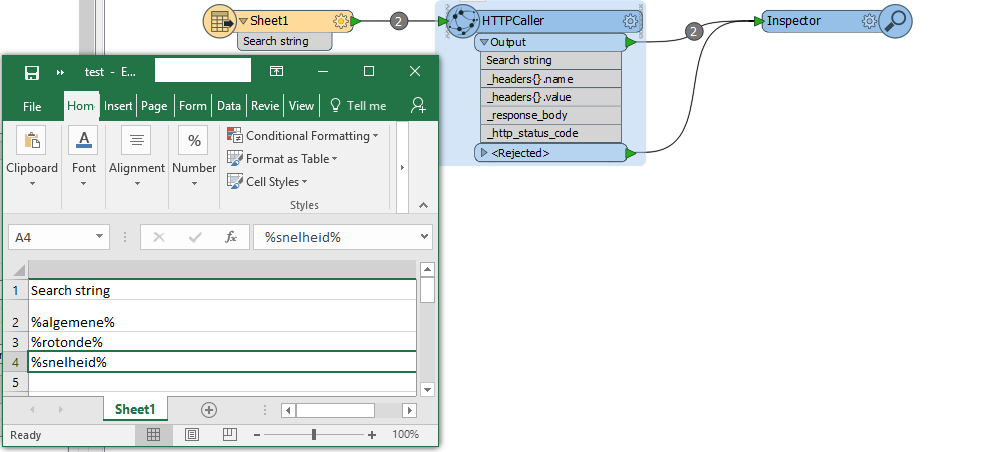
HTTPCaller setup:
Request URL has "@Value(Search string)" referring to input Excel file
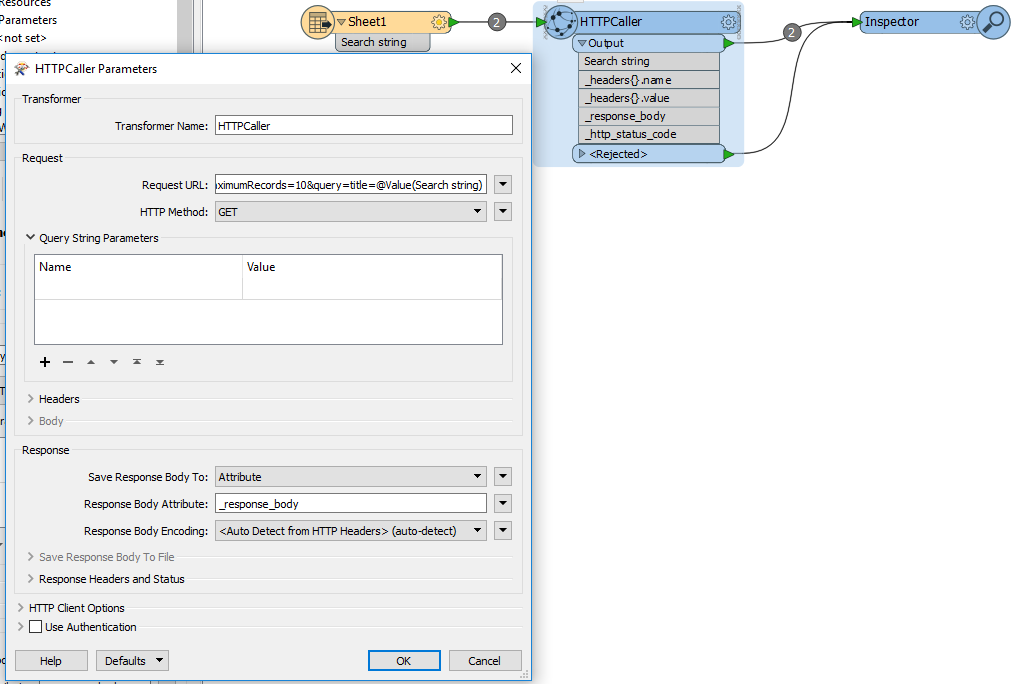
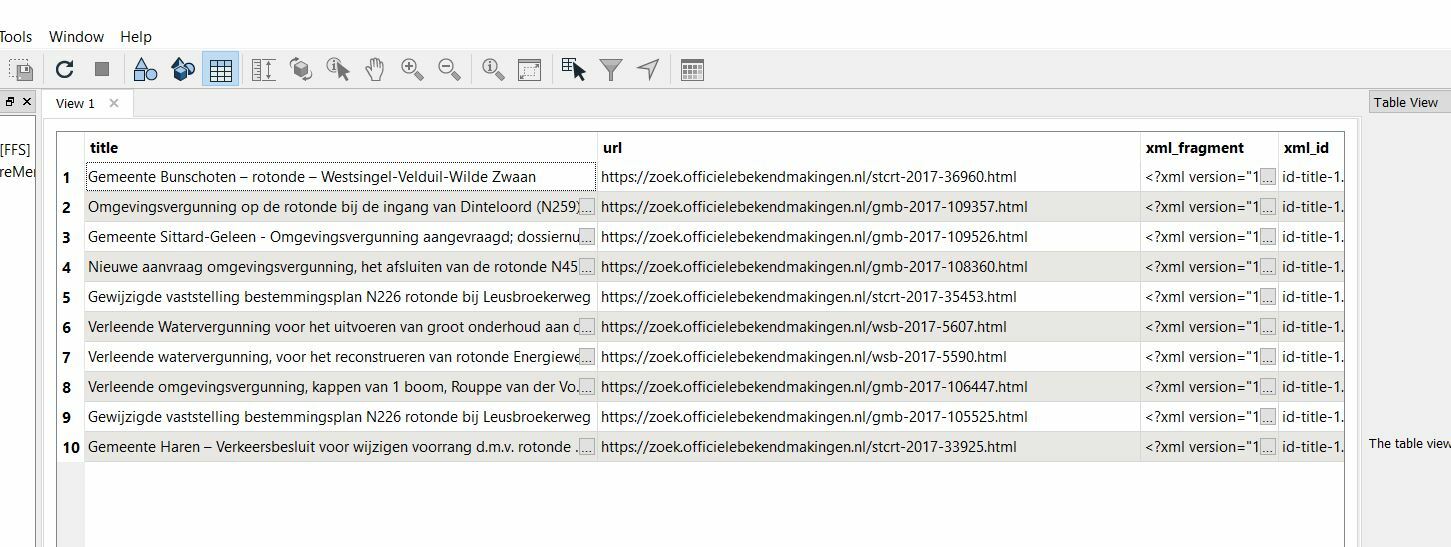
Output / errors:

*Edit
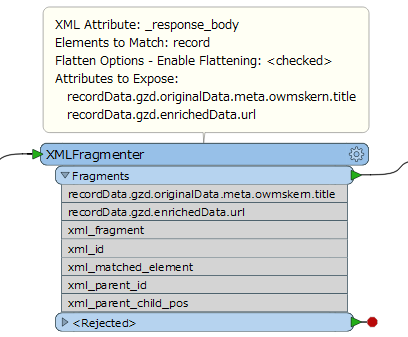
When inspecting the _response_body it seems I do have some XML data.
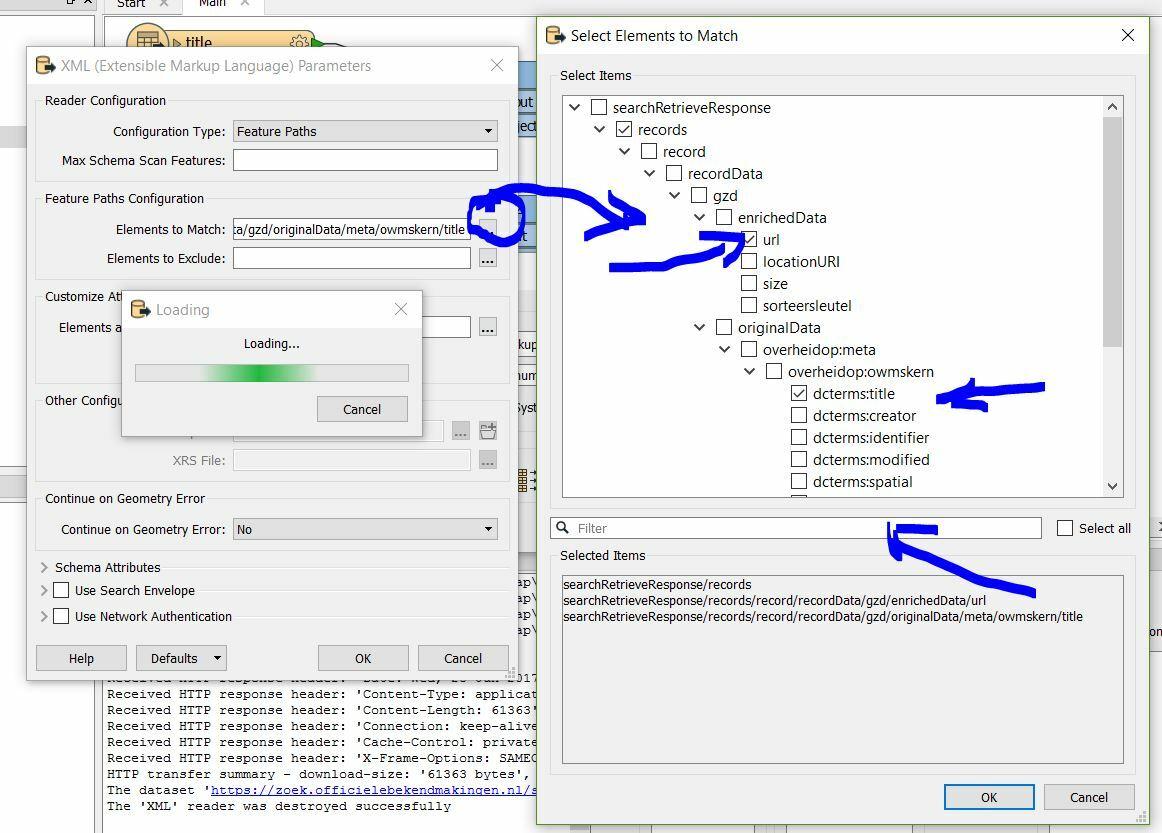
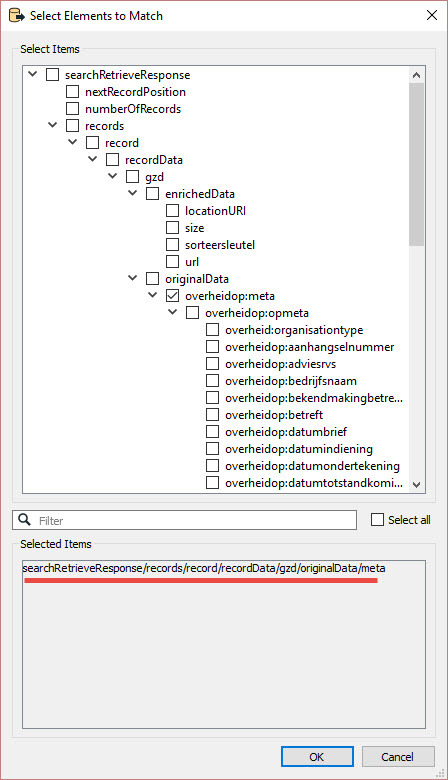
My next question, how to process this data? What transformers should I use next?
Many thanks,
Ed