")

Hi everyone,
I am brand new to FME and created my first workbench. In a nut shell it does this:
- Brings in 6 different enterprise geodatabase feature classes using 6 ESRI Geodatabase (ArcSDE Geodb) readers
- Each reader is connected to a tester to only select ‘active’ values in a status field
- Because I selected ‘resolve domains’ in the reader, an additional field for every field that had a domain was created. It was suffixed with “_resolved”, so I used 6 bulk attribute renamer transformers to rename the fields without the ‘_resolved”
- I then did 6 attribute removers and removed any fields I did not need when it came to exporting (note, many of the fields between each feature class were the same, but there were some differences)
- Finally, I used 6 different feature writers to export each feature class into a single geodatabase
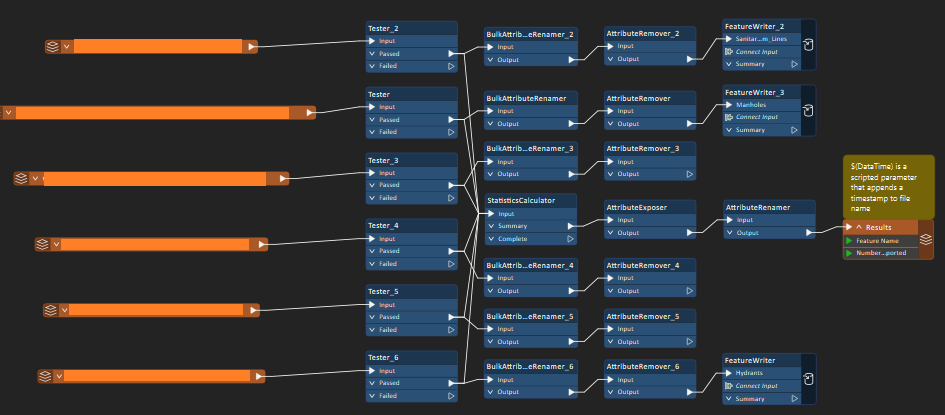
As you can see, I repeated the process 6 different times for every reader/feature class that I had. I was thinking to myself while doing this, ‘this cannot be the right way to do this, what if I had 100 layers to work with).
From there I tried recreating the workbench in a more streamlined way:
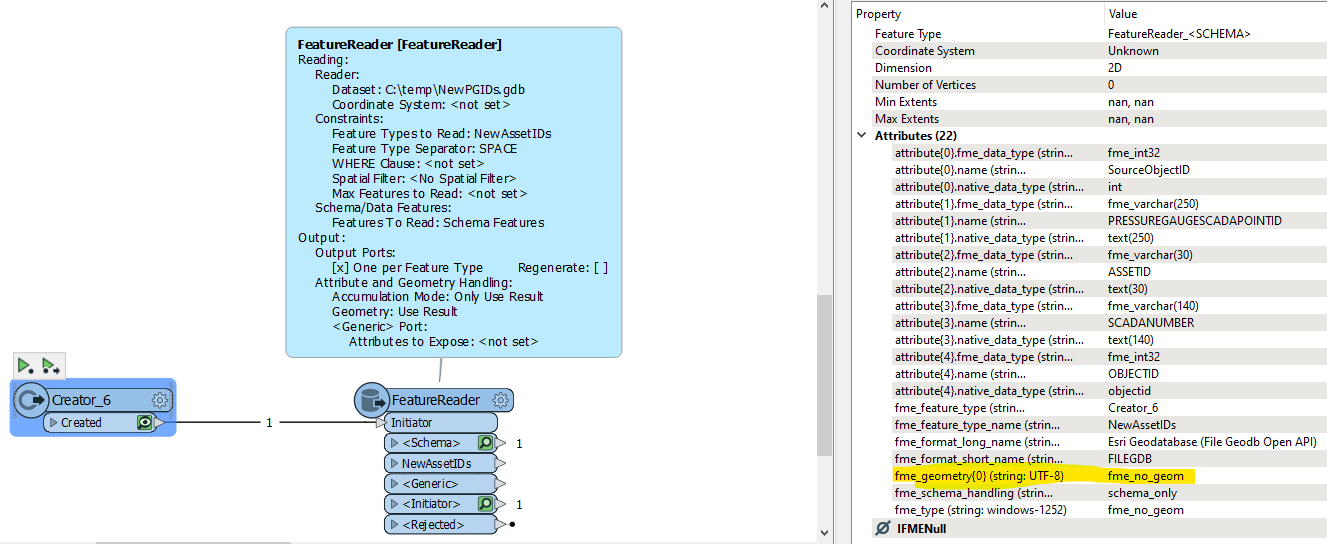
- Bring in the feature classes in their own individual reader
- Use a junction to connect each individual reader
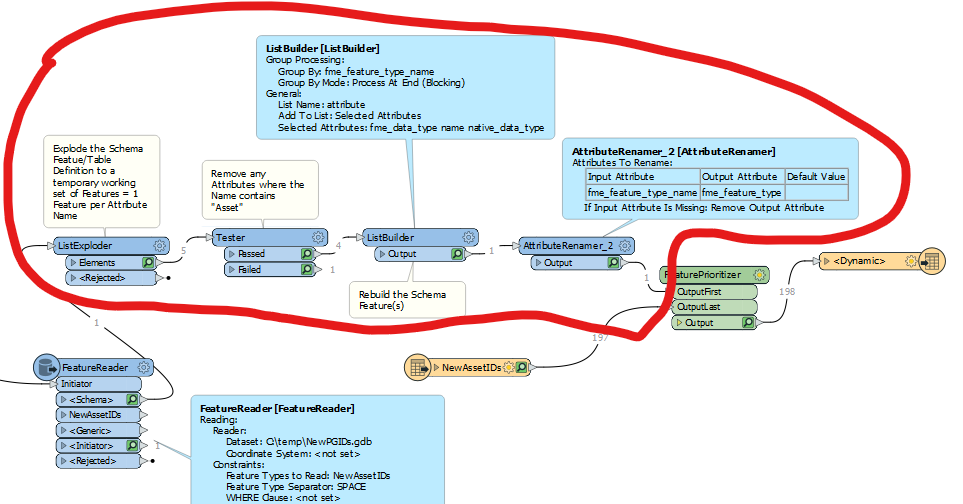
- Use a bulk attribute renamer to strip “_resolved” from any field that has it
- Use attribute remover to remove any field that I did not need (it gave me a list of every single field in every single feature class, which I really liked cause I could remove them all at once)
- Use a schema scanner to generate “fme_feature_type_name” with group processing selected, grouped by “fme_feature_type” to prepare for a dynamic file geodatabase writer
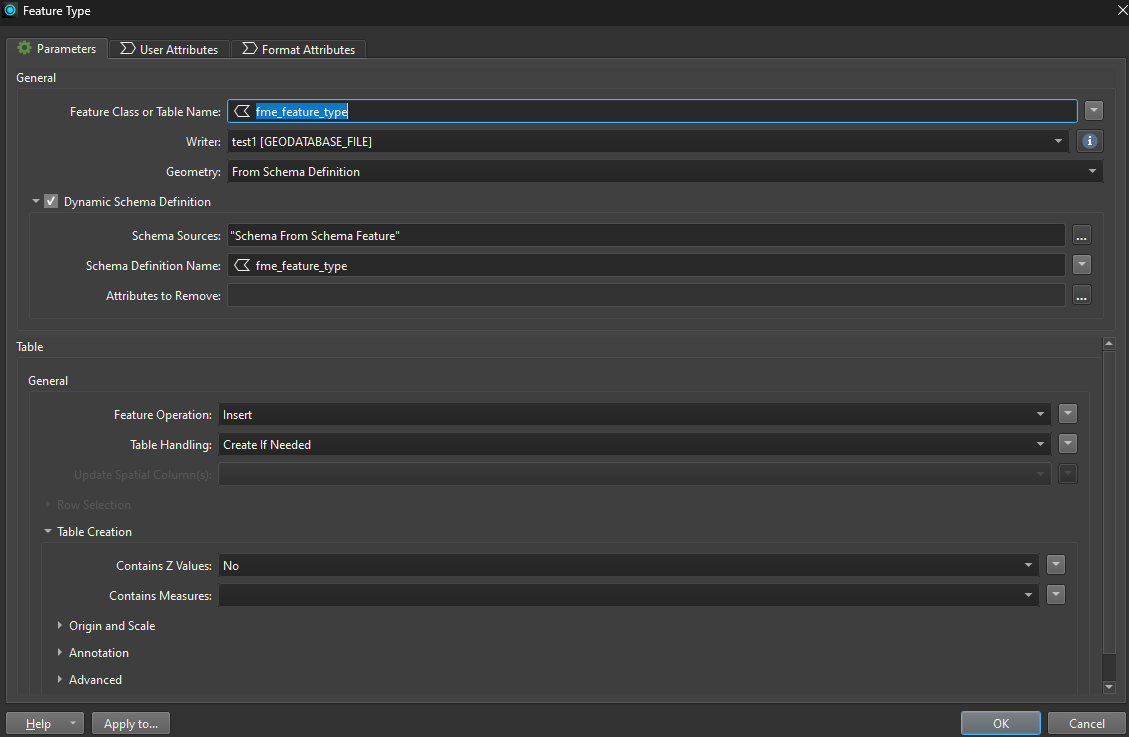
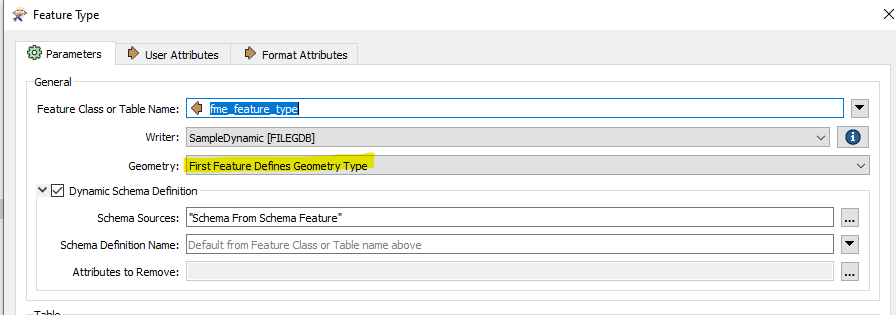
- Use a dynamic file geodatabase writer to export each feature class to a new geodatabase
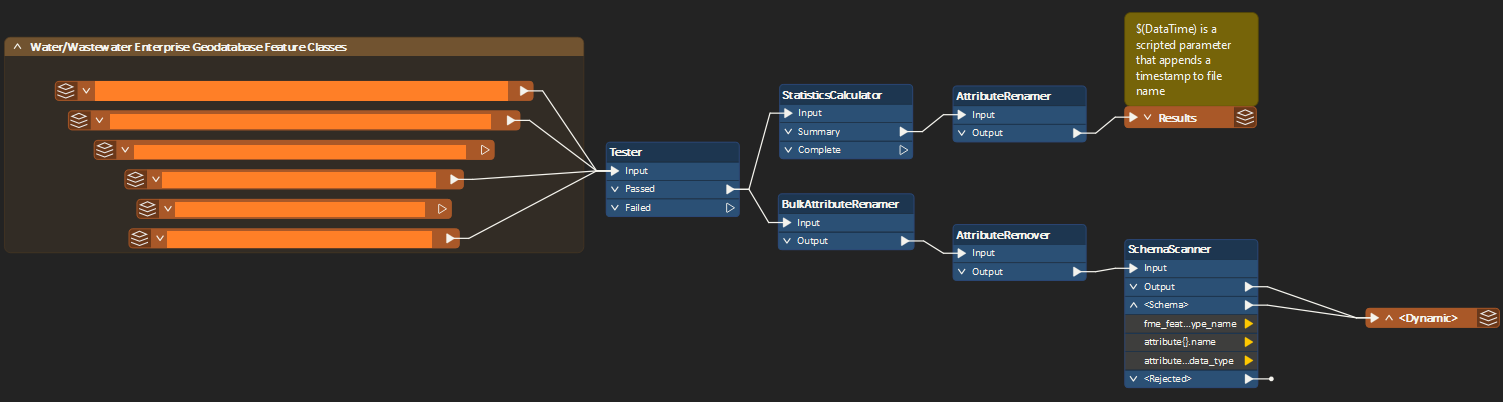
Unfortunately I was not able to get this to fully work, but I was close.
With that said, generally when working with FME, is the best practice to do everything individually? It seems very redundant (I come from a python background), and I am always looking for efficiency. Again, I am very new to FME, so hearing your input/ideas would be greatly appreciated, maybe there is something that I don’t know and could have made this more logical?
Thank you in advance for your time and attention, I look forward to the discussion!