
I am able to upload PDFs to SharePoint using FME, but the content I get from another system's API is coming in as a BLOB, then I have to convert this binary to Base64 then convert again to Unicode or Binary (System Default) like this:
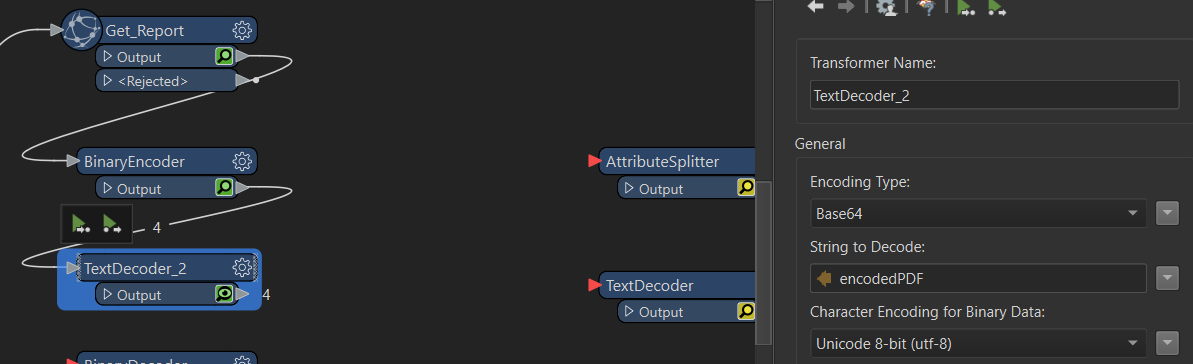 The output of the BinaryEncoder transformer is testably correct:
The output of the BinaryEncoder transformer is testably correct:
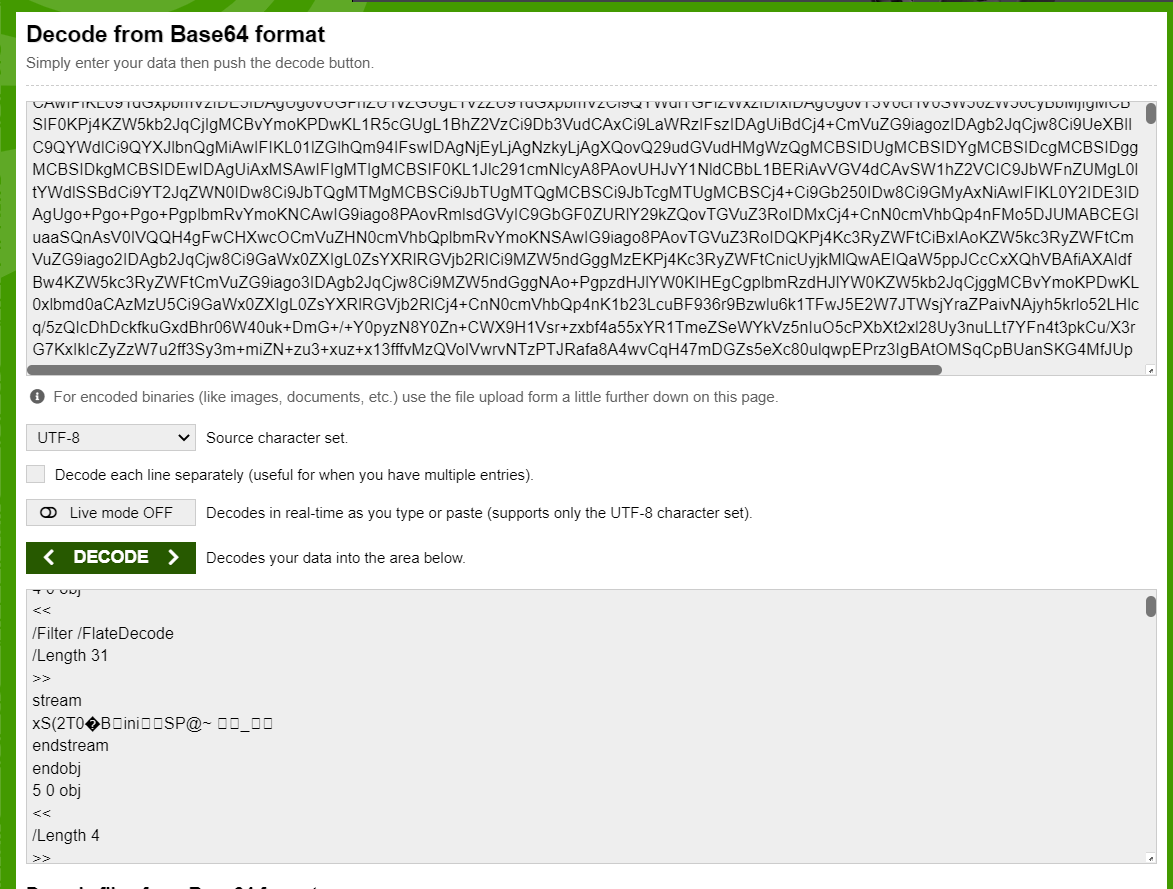 BUTT the TextDecoder is producing a trimmed output:
BUTT the TextDecoder is producing a trimmed output:
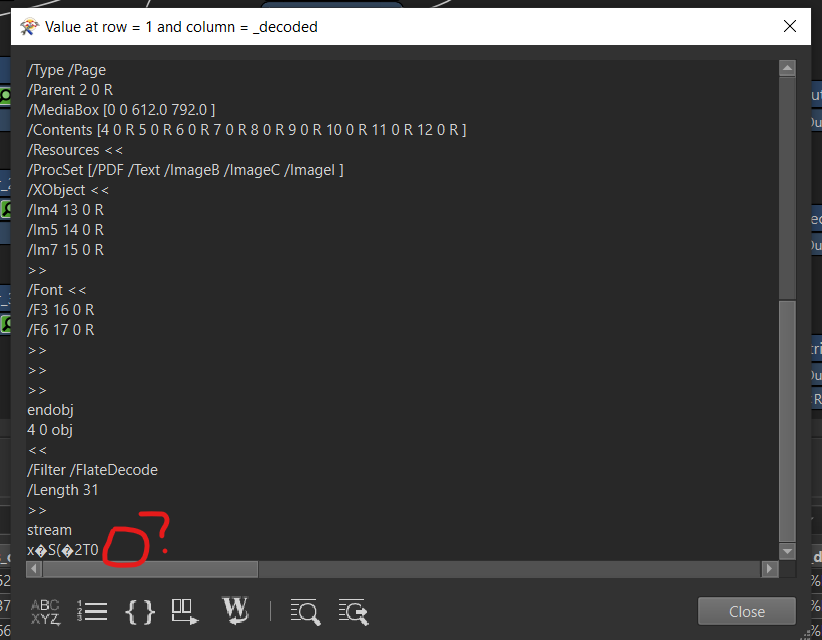 When I upload this file to SharePoint it is incomplete and lacks the actual PDF content, but is openable and not corrupt.
When I upload this file to SharePoint it is incomplete and lacks the actual PDF content, but is openable and not corrupt.
Is there a known limitation here, a setting that can be changed, or alternative workflows that would work here?
Thank you

