
Issue best described with some images:
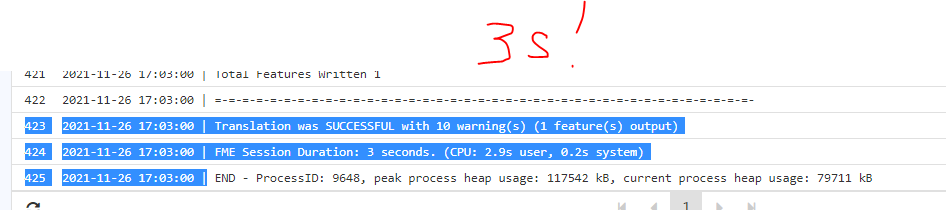
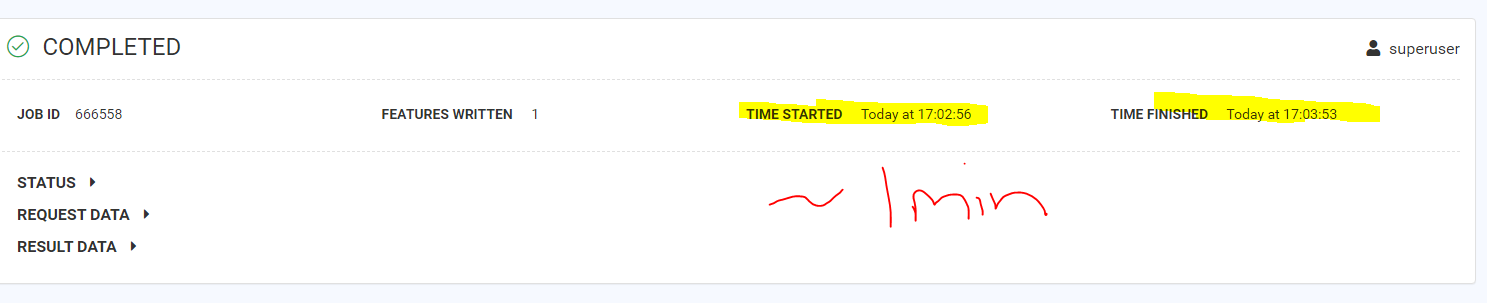
Anyone have any ideas as to why, before lunch it was running and reporting taking a few seconds, now it is taking a one minute but reporting as taking 3 seconds. I am running as a data stream.
Thank you


 +15
+15Issue best described with some images:
Anyone have any ideas as to why, before lunch it was running and reporting taking a few seconds, now it is taking a one minute but reporting as taking 3 seconds. I am running as a data stream.
Thank you
Best answer by itsmatt
Hmmm, it could be related to the how long it takes to send the response back to the client requesting the Data Streaming service. Do you see the same thing when using data download or job submitter?
Alternatively in some cases jobs will get resubmitted in the case they crash. It could be that the job is crashing and being restatrted. This is pretty unlikely though, you can check in the processmonitor log to see if there are any crashes.
Next is to check other logs, there should be a datastreaming log I think which might give you some clues as well
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.





