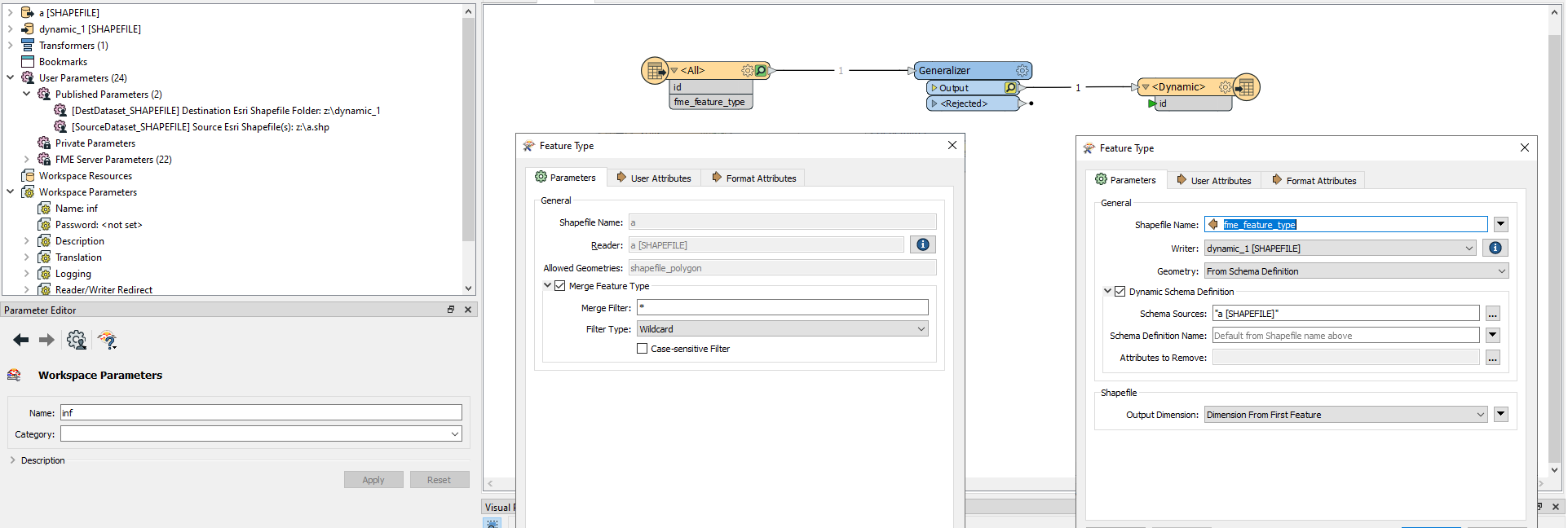
I have simple workspace doing a point densification and generalization on polygons:
I have three published parameters:
the input (Shapefile), the output directory and the output name (Shapefile).
I call it from a batch file (it is replacing another tool in a longer chain of commands) like this:
fme workspace.fmw --DestDataset_SHAPEFILE z:/ --ftp_feature_type_name_exp b
This works as intended, taking the default input (z:/a.shp) and writing to both directory and filename I define in the parameters (z:/b.shp)
fme workspace.fmw --SourceDataset_SHAPEFILE z:/b.shp --DestDataset_SHAPEFILE z:/ --ftp_feature_type_name_exp c
Using the --SourceDataset_SHAPEFILE parameter does not work. There is no error message, but it seems the workbench either does nothing or falls back to the default values for all parameters.
How can I call a workspace with different input/output data, from console? These are purely geometric operations, so I don't think schema should be an issue (it is the same in these examples).
Best answer by tomf
See attached workspace (FME2020.1.3.0) and data folders for an example of how this works, shapefile to shapefile. Data is borrowed from Safe's training material. The workspace currently uses relative paths to the input and output dataset where the filepath is relative to the saved location of the workspace. Apart from setting fme_feature_type to the new root filename required, I've added a BulkAttributeRemover to remove hidden format attibutes from the output schema definition (otherwise they get exposed in the output) and then used the custom transformer SchemaSetter to create the schema feature (attribute{}.name etc.). We then write the features out using a shapefile writer, fanning out on fme_feature_type and using the schema source set to "Schema from schema feature"To use: Set the source parameter to point at your input shapefile (there are 3 in the input folder to test with); set the new name parameter (no extension); and if you want to change the destination folder set the private parameter to point at the new location. Other functionality can be added into this workspace before or after the Prepare Features ... bookmark (after only if the extra process does not change the output schema).
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
Hi @riverag Does the translation create a log file? What command-line syntax do you see in blue at the top of your log window when you run the workspace in FME Workbench? If you haven't done that, you can also open your workspace in a text editor to see the syntax at the top. Also, if you have more than one installation of FME on your machine then you might want to include the full path to fme.exe in your batch file.
Although the process in your workspace might be purely geometry-based, FME still will check that the schema of the data being read matches the read schema defines in the FME reader. Data that does not match will be dropped.
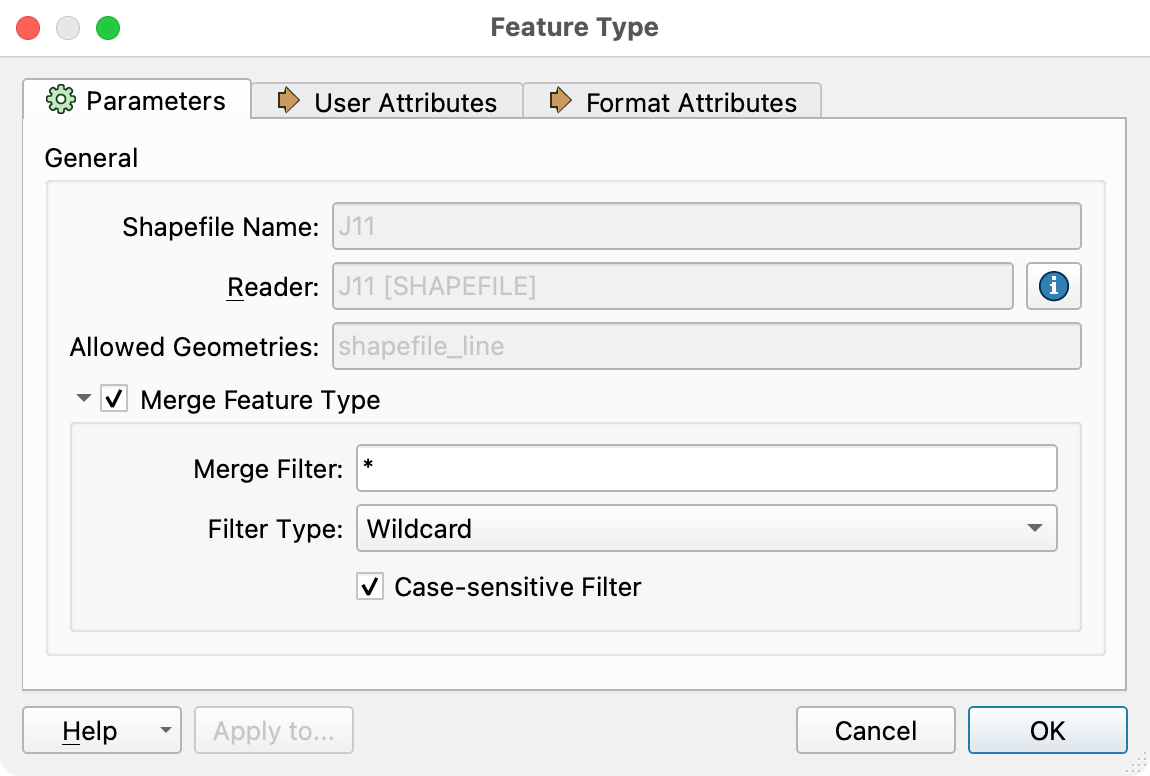
To get round this use dynamic reading - i.e. in the workspace, in the Reader Feature Type parameters, check the box marked "Merge Feature Type"
You can read more about dynamic workflows at this Safe tutorial.
Although the process in your workspace might be purely geometry-based, FME still will check that the schema of the data being read matches the read schema defines in the FME reader. Data that does not match will be dropped.
To get round this use dynamic reading - i.e. in the workspace, in the Reader Feature Type parameters, check the box marked "Merge Feature Type"
You can read more about dynamic workflows at this Safe tutorial.
this was very helpful and I can use the workspace several times in row now (example: a.shp->b.shp; b.shp->c.shp; c.shp->d.shp). This is already a step forward. However if I change the schema (add a field to c.shp for example), it still runs, but the output (d.shp) does not contain the field anymore. I am not sure if it is dropped because it doesn't fit the original input or the original output. I tried putting the output to "Dynamic Schema Definition", but after that it would only write features with the same name as the input (e.g. z:/a.shp to z:/output/a.shp). Why is that?
I cannot exately get my head around these kinds of problem in FME (haven't been using it for long), but in order to make these workspaces reusable, I should be able to make workbenches somewhat detached from the input data (especially for purely gemetric operations)? If I have 100 datasets to process, how else would I do it?
On a related note, why is the setting called "Merge Feature Type"? In what sense is this a merge?
Hi @riverag Does the translation create a log file? What command-line syntax do you see in blue at the top of your log window when you run the workspace in FME Workbench? If you haven't done that, you can also open your workspace in a text editor to see the syntax at the top. Also, if you have more than one installation of FME on your machine then you might want to include the full path to fme.exe in your batch file.
Hey Dan,
thanks for the input, I didn't realise I could also see the command line in the log window, very helpful. It's using the same syntax as me though.
I made some progress using @tomf 's recommendation, which only lead to further questions though.
@riverag, you are correct in that if your source schema is changing you will need to use dynamic writing to preserve all the attributes in the output dataset. Dynamic writing still relies on FME knowing a schema definition for all the features being written — this defaults to being the reader schema definition. There is a hidden fme-attribute called fme_feature_type which holds the source feature type name on each feature and this is used to tie a feature to a particular schema definition (schema: feature type name + attribute names and data types + geometry type (if applicable)). In the writer when using dynamic writing, FME defaults the feature type name to be the value of fme_feature_type, and this is why your shapefiles end up with the same name.
You can manipulate the feature type name (and in your case the shapefile name) by changing the value of feature_type_name in an AttributeManager or similar. I suspect you will also need a diffferent schema source — I'd suggest using the FeatureReader to generate the schema (see the "schema from list feature" idea described in this part of the Dynamic workflows tutorial) changing the value of fme_feature_type for every feature (schema and data) before writing out.
Regarding "Merge Feature Type". From an FME point of view, if we imaging that the reader is a database reader reading from many tables (with a variety of schema) we could potentially end up with 10s or even 100s of Reader Feature Type objects on the canvas. Often they will all run into a single workflow. Either way they take up an awful lot of space on the canvas and can be confusing. Using "Merge Feature Type" allows all of these feature types to be read into the workspace through a single Reader Feature Type object, i.e., all of the Reader Feature Types have been 'merged' into one creating a union of all the read features on a single data stream. In your case we are leveraging this functionalilty to accept datasets/feature types with different schemas, even though we're only reading one dataset at a time.
I hope this helps your FME understanding. I probably should point out that dynamic workflows are considered 'advanced' and you will find them easier to understand with a good grounding in the basics of FME.
@riverag, you are correct in that if your source schema is changing you will need to use dynamic writing to preserve all the attributes in the output dataset. Dynamic writing still relies on FME knowing a schema definition for all the features being written — this defaults to being the reader schema definition. There is a hidden fme-attribute called fme_feature_type which holds the source feature type name on each feature and this is used to tie a feature to a particular schema definition (schema: feature type name + attribute names and data types + geometry type (if applicable)). In the writer when using dynamic writing, FME defaults the feature type name to be the value of fme_feature_type, and this is why your shapefiles end up with the same name.
You can manipulate the feature type name (and in your case the shapefile name) by changing the value of feature_type_name in an AttributeManager or similar. I suspect you will also need a diffferent schema source — I'd suggest using the FeatureReader to generate the schema (see the "schema from list feature" idea described in this part of the Dynamic workflows tutorial) changing the value of fme_feature_type for every feature (schema and data) before writing out.
Regarding "Merge Feature Type". From an FME point of view, if we imaging that the reader is a database reader reading from many tables (with a variety of schema) we could potentially end up with 10s or even 100s of Reader Feature Type objects on the canvas. Often they will all run into a single workflow. Either way they take up an awful lot of space on the canvas and can be confusing. Using "Merge Feature Type" allows all of these feature types to be read into the workspace through a single Reader Feature Type object, i.e., all of the Reader Feature Types have been 'merged' into one creating a union of all the read features on a single data stream. In your case we are leveraging this functionalilty to accept datasets/feature types with different schemas, even though we're only reading one dataset at a time.
I hope this helps your FME understanding. I probably should point out that dynamic workflows are considered 'advanced' and you will find them easier to understand with a good grounding in the basics of FME.
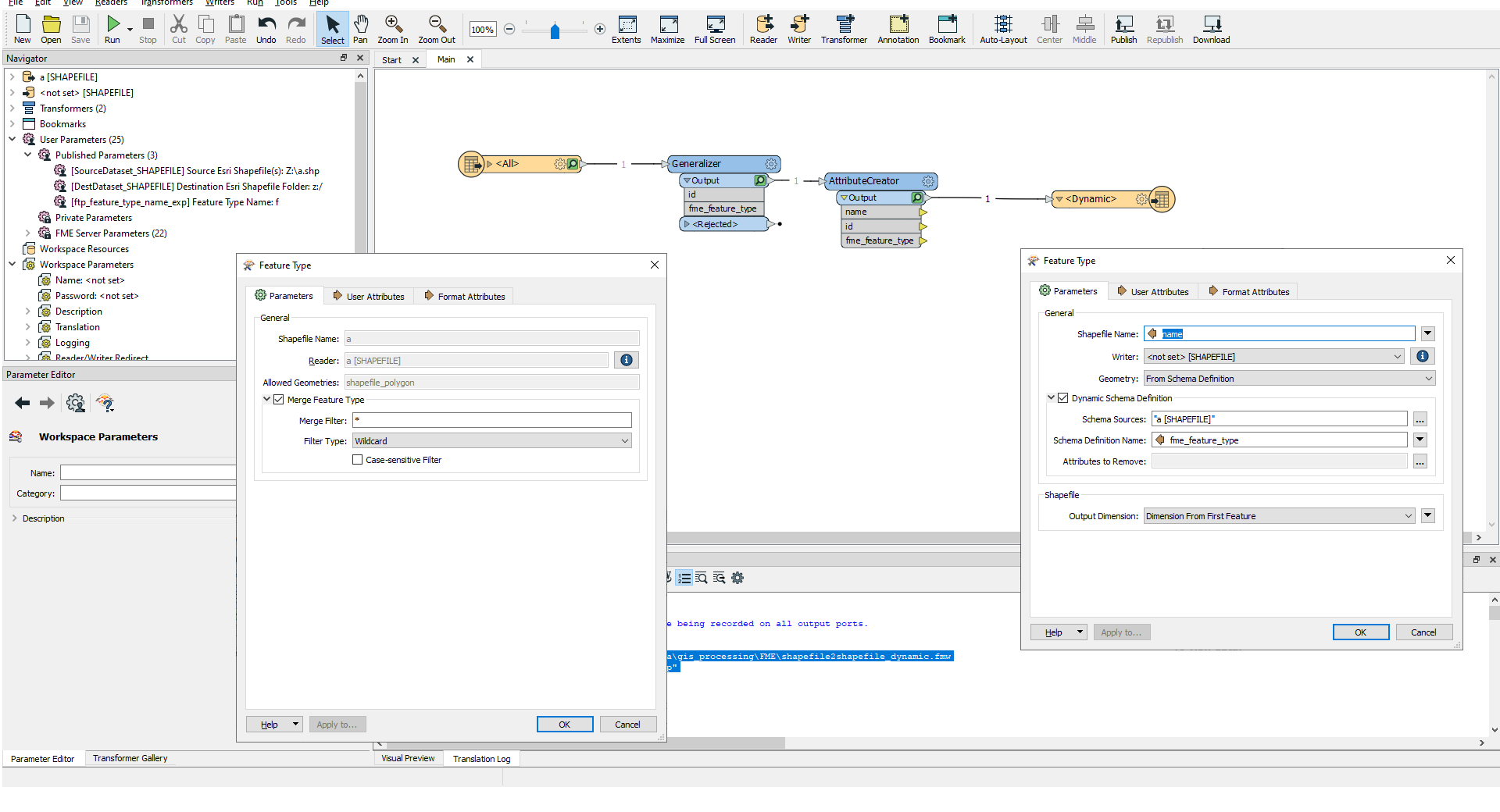
Thank you for your response. I looked at the tutorials regarding dynamic workspaces and came up with this:
This basically does everything I want, but the input name (e.g. "a.shp", "b.shp", "c.shp"), is identical with the output name. I can work around the overwriting part by using a different output path (e.g. z:/dynamic_1). But in a longer batch process, I would like to avoid having to copy back all files, rename them etc.
I generate a field "name" and fill it with a value through a user paramter. The writer takes the attribute "name" as the output name. The output is then written correctly to the <output path>/<name>.shp, (z:/b.shp, for example). Unfortunately this only works if the input is exactely z:/a.shp! So the "dynamic" part of the reader is somehow lost on the way. If I run it with input "z:/b.shp" it doesn't even seem to read any features (despite the presence of said Shapefile).
Creating writer for format: Creating reader for format: MULTI_READER(MULTI_READER): Will fail with first member reader failure Using Multi Reader with keyword `MULTI_READER' to read multiple datasets Using MultiWriter with keyword `MULTI_WRITER' to output data (ID_ATTRIBUTE is `multi_writer_id') Writer output will be ordered by value of multi_writer_id Loaded module 'LogCount_func' from file 'C:\Program Files\FME\plugins/LogCount_func.dll' FME API version of module 'LogCount_func' matches current internal version (3.8 20200115) Emptying factory pipeline Router and Unexpected Input Remover (RoutingFactory): Tested 0 input feature(s), wrote 0 output feature(s): 0 matched merge filters, 0 were routed to output, 0 could not be routed. Unexpected Input Remover Nuker (TeeFactory): Cloned 0 input feature(s) into 0 output feature(s) a_SHAPEFILE_1 Splitter (TeeFactory): Cloned 0 input feature(s) into 0 output feature(s) Destination Feature Type Routing Correlator (RoutingFactory): Tested 0 input feature(s), wrote 0 output feature(s): 0 matched merge filters, 0 were routed to output, 0 could not be routed. Final Output Nuker (TeeFactory): Cloned 0 input feature(s) into 0 output feature(s) =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=- Features Read Summary =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=- ============================================================================== Total Features Read 0 =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=- =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=- Features Written Summary =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=- ============================================================================== Total Features Written 0 =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=- -~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~- -~ ~- -~ Feature caches have been recorded at every stage of the translation. ~- -~ To inspect the recorded features, ~- -~ click the feature cache icons next to the ports. ~- -~ ~- -~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~- Translation was SUCCESSFUL with 7 warning(s) (0 feature(s) output) FME Session Duration: 0.8 seconds. (CPU: 0.0s user, 0.1s system) END - ProcessID: 12948, peak process memory usage: 45092 kB, current process memory usage: 45092 kB Translation was SUCCESSFUL
See attached workspace (FME2020.1.3.0) and data folders for an example of how this works, shapefile to shapefile. Data is borrowed from Safe's training material. The workspace currently uses relative paths to the input and output dataset where the filepath is relative to the saved location of the workspace. Apart from setting fme_feature_type to the new root filename required, I've added a BulkAttributeRemover to remove hidden format attibutes from the output schema definition (otherwise they get exposed in the output) and then used the custom transformer SchemaSetter to create the schema feature (attribute{}.name etc.). We then write the features out using a shapefile writer, fanning out on fme_feature_type and using the schema source set to "Schema from schema feature"To use: Set the source parameter to point at your input shapefile (there are 3 in the input folder to test with); set the new name parameter (no extension); and if you want to change the destination folder set the private parameter to point at the new location. Other functionality can be added into this workspace before or after the Prepare Features ... bookmark (after only if the extra process does not change the output schema).
See attached workspace (FME2020.1.3.0) and data folders for an example of how this works, shapefile to shapefile. Data is borrowed from Safe's training material. The workspace currently uses relative paths to the input and output dataset where the filepath is relative to the saved location of the workspace. Apart from setting fme_feature_type to the new root filename required, I've added a BulkAttributeRemover to remove hidden format attibutes from the output schema definition (otherwise they get exposed in the output) and then used the custom transformer SchemaSetter to create the schema feature (attribute{}.name etc.). We then write the features out using a shapefile writer, fanning out on fme_feature_type and using the schema source set to "Schema from schema feature"To use: Set the source parameter to point at your input shapefile (there are 3 in the input folder to test with); set the new name parameter (no extension); and if you want to change the destination folder set the private parameter to point at the new location. Other functionality can be added into this workspace before or after the Prepare Features ... bookmark (after only if the extra process does not change the output schema).
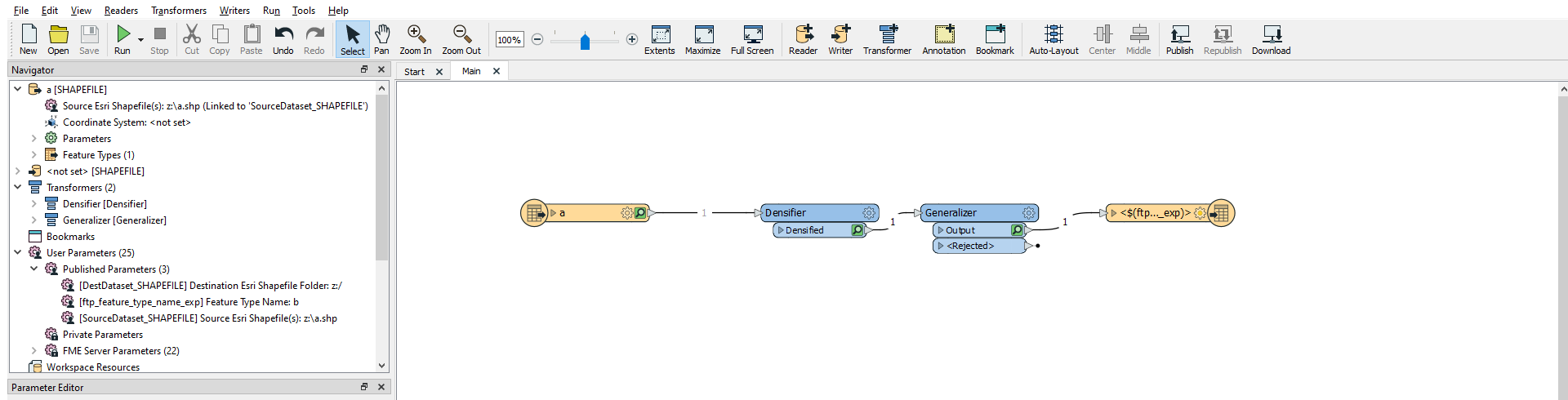
This works!
Thank you for your answer. Just to further my understanding: is it correct to say that the fme_feature_type attribute is just a regular attribute you can change back and forth and only using the SchemaSetter it becomes relevant (or readable?) to the writer?
Thank you for your answer. Just to further my understanding: is it correct to say that the fme_feature_type attribute is just a regular attribute you can change back and forth and only using the SchemaSetter it becomes relevant (or readable?) to the writer?
fme_feature_type is a hidden attribute that FME uses to keep track of what feature type a feature belongs to. Once its exposed, we can manipulated it just like any other attribute. The SchemaSetter automatically ignores it in the schema definition list it creates. In the Writer we are defining the feature type name as the value of fme_feature_type, which means that in the source of the schema it has to be able to find a table definiton of the same value.
In the example workspace, the schema source is on the features, so the value of fme_feature_type, and hence the output shapefile name, is the same, resulting in a matched schema and complete output.

 I have three published parameters:
I have three published parameters: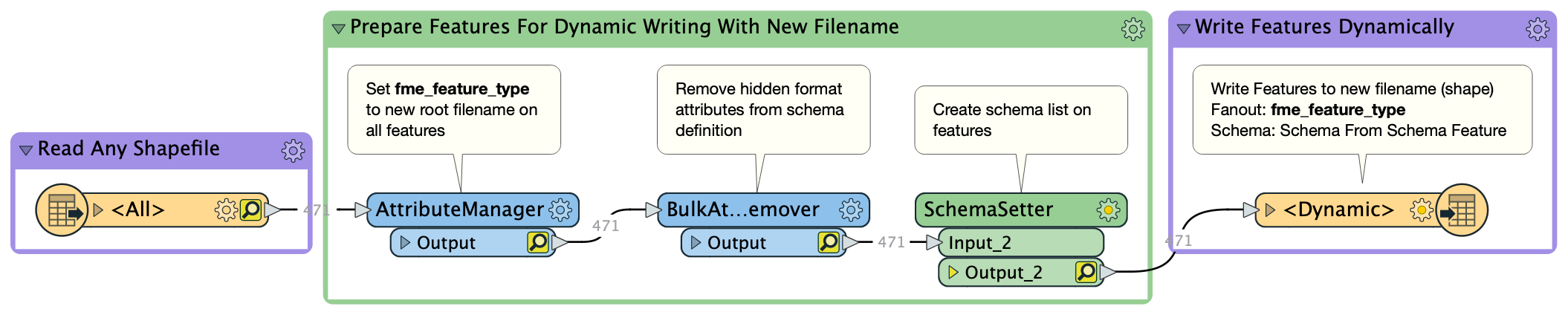 To use: Set the source parameter to point at your input shapefile (there are 3 in the input folder to test with); set the new name parameter (no extension); and if you want to change the destination folder set the private parameter to point at the new location. Other functionality can be added into this workspace before or after the Prepare Features ... bookmark (after only if the extra process does not change the output schema).
To use: Set the source parameter to point at your input shapefile (there are 3 in the input folder to test with); set the new name parameter (no extension); and if you want to change the destination folder set the private parameter to point at the new location. Other functionality can be added into this workspace before or after the Prepare Features ... bookmark (after only if the extra process does not change the output schema).





 You can read more about dynamic workflows at this Safe
You can read more about dynamic workflows at this Safe