Hi all,
I need to extract the Hex Code Point of multiple letters using TextEncoder.
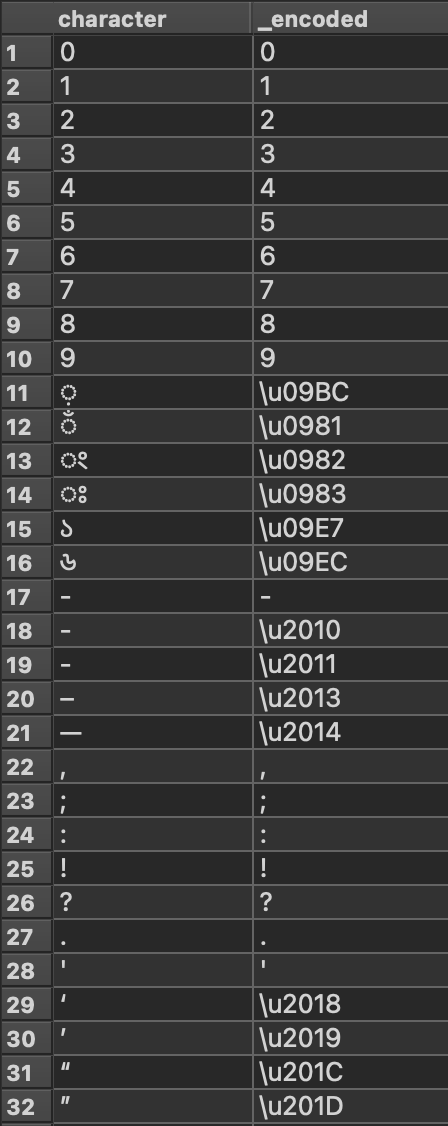
However, the transformer fails to encode Roman numbers and some special characters. You can see in the below screenshot that it successfully encodes Bengali letters and some special characters, but not the others.
Anyone has an idea how to solve it or any workarounds? Thanks!