

I'm reading a couple of files, and they have some matching attributes. I want to rename those attributes in one go, but write the files with their original attribute structure only. However when I write the files, they all end up with the combined attributes. Filtering empty attributes is not possible because some files have attributes with no values. Copying the reader settings on the writer(s) also doesn't work out because the names would be wrong. Is there a way to keep the original structure, with the new names?
Basically this:
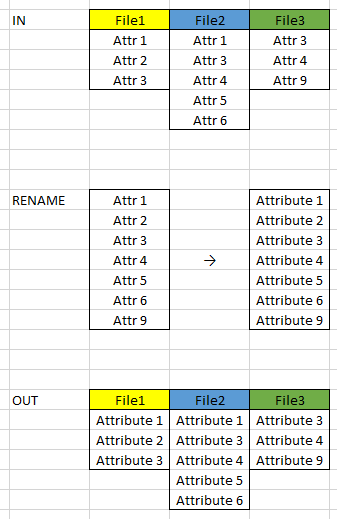
")
