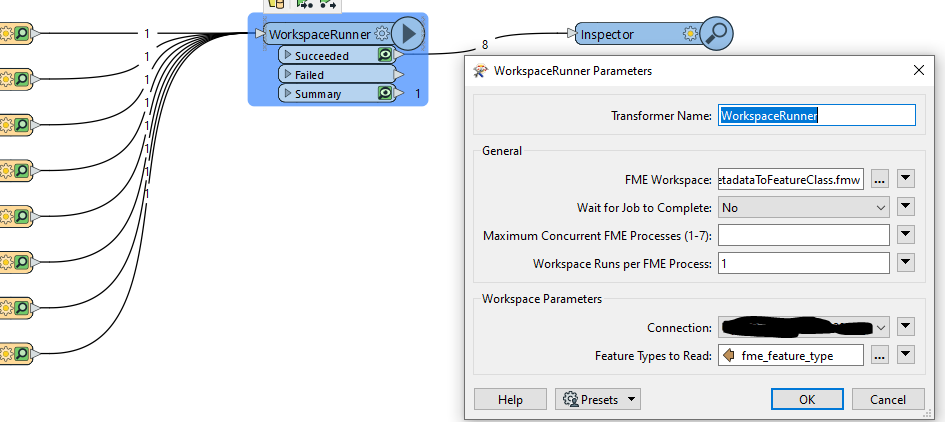
I've created a workbench in FME Database Edition 2022.1.3 that reads the existing metadata of a feature class in an ArcGIS Enterprise Geodatabase (SQL Server), and updates certain components of the metadata based on a table in another database where the feature class name matches the "Name" field in that table. This works for one feature class in the GDB at a time. Is there a way to iterate over all feature classes in the GDB and run the workbench against each one, one at a time? I've tried adding multiple feature classes as a Single merged feature type, and as individual feature types, and it is not updating the metadata as expected. It seems to update the metadata to the same values for all feature classes.
thanks



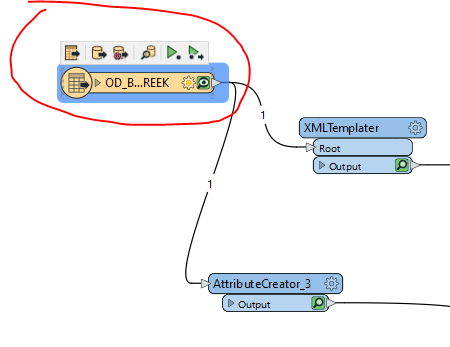 i.e. that reader should be replaced by each table read in the WorkspaceRunner.
i.e. that reader should be replaced by each table read in the WorkspaceRunner.