


Hi FME'ers,
This question was asked about Excel data, but it often applies to any text-based format where a set of records is subdivided by a separate header record. In this scenario, the header record gets read as a standard feature by FME. It needs not just to be filtered out, but its contents added to adjacent records.
Question of the WeekQ) I am trying to use FME to get some excel data formatted. The problem is there are headers which I need to populate as a column. I tried using the VariableSetter but it gives me the same header all the way through for all the lines.
https://knowledge.safe.com/questions/104160/variable-setter.html
A) Workflows - or the flow of features through a workspace - is an aspect of FME that is important for keen workspace authors to be aware of. In fact I recently wrote a post on feature order for 2019.2. Why does this apply here? It's because the user wants to pass information from one feature to another, not using a common attribute value, but on the basis of their proximity in the Excel file.
Let's see why...
The ChallengeSo what the user has here is effectively this:
HEADER A
Feature 1
Feature 2
HEADER B
Feature 3
Feature 4What they want is to apply the header to subsequent features, giving them:
Feature 1,A
Feature 2,A
Feature 3,B
Feature 4,BSo we need to be able to take that header and store it somewhere, in order to apply it to subsequent features. There are two ways to do that: what I call the "right way", and the "old right way".
VariablesA variable is like an attribute that belongs to the entire workspace, not just one feature. One feature can set a variable (VariableSetter) and another one can retrieve it (VariableRetriever). Here the solution would be for the Header feature to set the variable (with the header value) and the feature record to retrieve it:
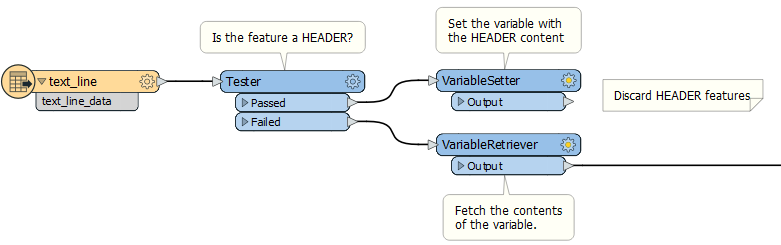
However, this solution gives us a strict set of requirements regarding the order of operations...
- Header A must set the variable before Features 1 and 2 retrieve it
- Header B must not set the variable until features 1 and 2 have retrieved Header A
- Features 3 and 4 must not retrieve the variable until Header B has set it
- Features 1,2,3,4,etc must be a separate stream so as not to also set the variable
So controlling the order of features is vitally important in this scenario.
Adjacent Feature AttributesAdjacent Feature Attributes is a way where we give one feature the ability to fetch the attributes of a previous (or subsequent) feature. Here the solution is to give Feature 1 access to the information from the previous feature (Header A):
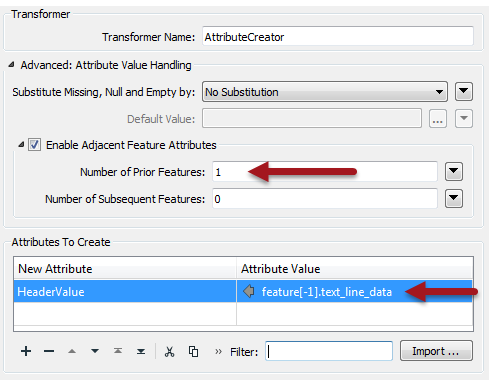
What about feature 2? Well, Feature 2 fetches its value from Feature 1, which had already fetched it from Header A. What you end up with is a temporary attribute that stores the header value and gets updated whenever the current feature is a new header.
This too depend on the order of features, so what's the difference?
The Preferred SolutionNotice that I didn't mention which is the right way and which is the old right way.
Variables are the old way. I don't say it's wrong, but personally I don't like to use them any more. As this user found out, it's harder to predict the order of features because you need to split the features into multiple streams (notice how the VariableSetter and VariableRetriever are on different connections).
Additionally, variables don't work as well with Bulk Feature mode. I didn't mention it in that previous article, but variables are affected by bulk mode because bulk mode changes the order. You are likely to get both Header A and Header B emerge from the Tester:Passed port and set the variable, before any Features emerge from the Failed port, and I think that's what the user in this case found out.
With adjacent attributes it's much easier to predict the order of features because you don't need to split up the data into separate streams.
Other Notable QuestionsThis week the other questions that particularly interested me were these...
- FFS Format Versions and Compatibility.
- FFS is updated all the time to accommodate new functionality in FME. This means that, although it is backwards compatible (new FME can read old FFS files), it's not the case that old FME can read new FFS files. So - to answer the question - FFS is not a reliable data storage format when you may be using a variety of FME versions.
- Combining Audio Format Files.
- As noted, it would be fairly straightforward to play different audio files in a set order, but merging files together would be tougher. Generally you would need to strip the header off the second file and then combine it onto the end of the first file. I've done this before using ASCII-type files (like pen plotter plt files) but binary audio files would be a different beast. I guess that you'd use the BinaryEncoder to convert to Hex, remove the correct number of bytes, convert back to binary, and write the data out (updating the first feature's header as necessary). In other words... hard work!
- Dynamically create attributes from a list.
- I haven't really looked at this one in depth, but it seems to me to be the old story of attaching attributes but then having to try create the schema to match. Here's the previous Question-of-the-Week where I talked about that.
Other News
Apologies for the lack of log-in capability yesterday. We're hoping this problem won't repeat. And it didn't - today's issue was something different. I apologise for the slowdown today. We're aware it's not a good position and we're actively working on a solution. As always, status details can always be found on status.safe.com




