


Hi FME'ers,
I found quite a few questions this week that I would like to highlight, but in the end I went with this one because it was something I was dealing with for the last couple of days. It's all about the FeatureJoiner transformer, and the oddities that make it a little different to other FME transformers.
Question of the WeekQ) I have two tables that I want to merge using a FeatureJoiner. When I ran the program, I found that about 100 records went into the rejected output field. When I investigated I found that the column I used from the left table to join has null values. Could anyone guide me on how could I make sure that all records from left table come to the output table?
Asked here by @muhammad_yasir
A) It's not too difficult to sort this out - you just need to filter those records to bypass the transformer - but I think it highlights what makes the FeatureJoiner a little different, so let's take a look at those differences...
The FeatureJoiner
The scenario is that we wish to join two sets of features together with a common attribute key. For the longest time we had a transformer called the FeatureMerger that used to do this. But the FeatureMerger started to be relatively slow, and so we created a new transformer called the FeatureJoiner to take its place.
The FeatureJoiner is a stripped-down version of the FeatureMerger, designed for speed and simplicity. But sometimes you need the complexity of the FeatureMerger, to handle a specific use case, and this is one of those occasions.
Handling Null KeysSo the issue is that the user's data has null key values. Here's an example of my own:
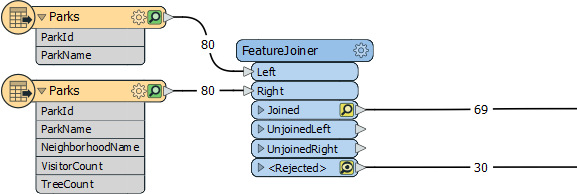
I'm joining attributes onto park features. The ParkName is the attribute key used to join, but some of the ParkName values are null. There are 15 parks with a null name and both Left and Right inputs for them get rejected.
The FeatureMerger transformer had a parameter to deal with this directly:
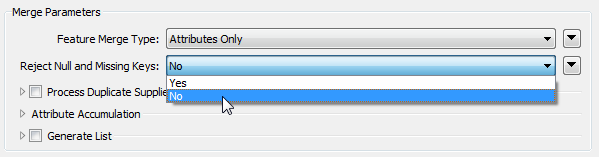
The FeatureJoiner is stripped-down, and does not have the same functionality. So, there are a couple of choices. The first is to test for null values and have those features bypass the FeatureJoiner. This is the answer suggested by @bwn
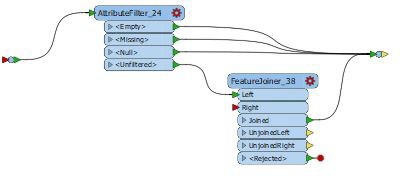
The other method would be to use a NullAttributeMapper to give the parks a dummy name:
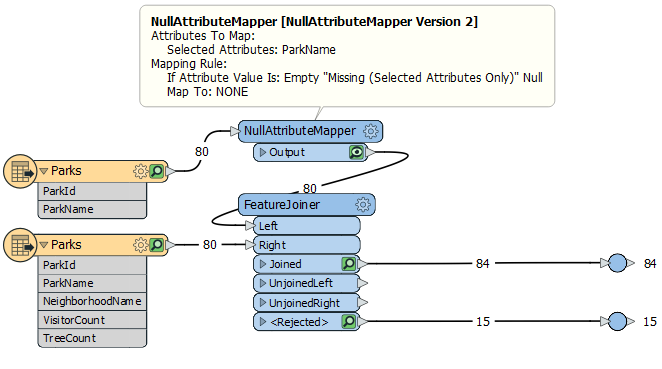
Now they come out of the Joined point.
Join ModeYou might now be wondering why these features are Joined, when they have a dummy name that shouldn't match to anything.
That's because the FeatureJoiner has a mode parameter to control what counts as a join:
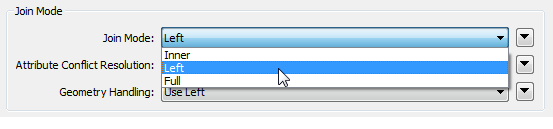
A Left join means all Left features emerge from the Joined port, regardless of whether they found a match or not. An Inner join would be the way to have unmatched Left features emerge from the UnjoinedLeft port:
This is an advantage the FeatureJoiner has over the FeatureMerger. It lets you better handle what counts as a join.
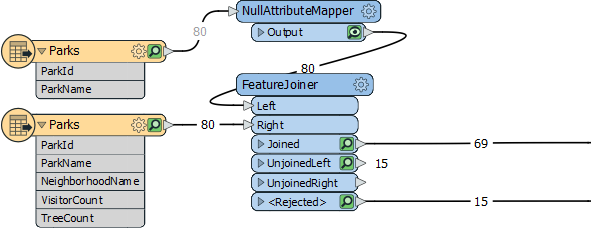
But you might also be wondering how 80 input features can lead to 84 output features...
Duplicate SuppliersThe reason for the extra output features is duplicates in the data. In short there are two features called Strathcona Park, and two features called Hadden Park.
The FeatureJoiner creates a join for every match, and outputs a feature for every join. Hence there are 65 features with valid keys, but 69 joins (each Strathcona Park and Hadden Park has two matches, not one).
The FeatureMerger handles this scenarios with a parameter called Process Duplicate Suppliers:
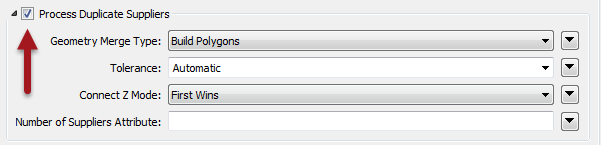
By turning that off, I will only get a join per key, regardless of the number of keys that match.
This is the issue I was dealing with recently. I wanted to know which users on this site had asked a question. So I fed the users and questions table into a FeatureJoiner:
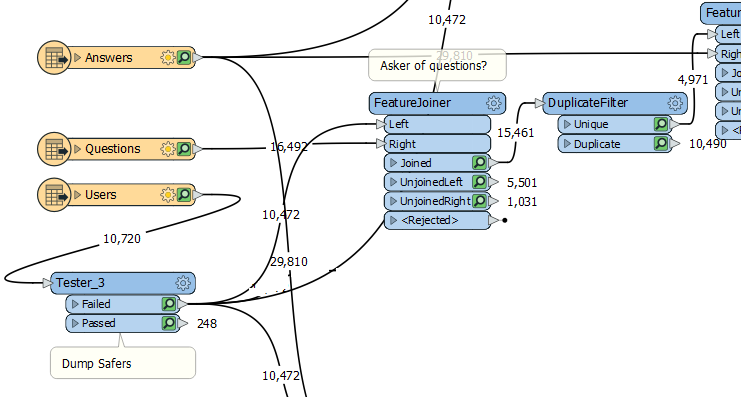
Notice that I got 15,461 joins. It created me a feature for every match between Users and Questions. That's why I plugged in a DuplicateFilter transformer, to keep just a set of users who have asked questions, not all of the questions as well.
The result... 4,971 different accounts have asked questions on this site, which is what I wanted to know.
If I really did want a list of questions per user, I could have used an Aggregator instead to create a list attribute for each of those 4,971 users.
Why did I not use the FeatureMerger? Because I figure this will actually run quicker. The FeatureJoiner is so much faster that the overall processing time is reduced, even if I need to throw an extra transformer in there.
SummaryIn summary, the FeatureMerger is more like the FME transformers we are used to; it has all sorts of parameters and options to control all different scenarios.
The FeatureJoiner is sparser in terms of parameters. You have fewer options to control it. However it runs so quickly that it's worth using. Plus, if you don't want the complexity, you don't get confused by irrelevant parameters.
You just have to be aware - as this question showed - that extra steps may be needed before and after.
Other Notable QuestionsLike I mentioned, there were quite a few questions of interest this week...
- Attributes in MicroStation DGN
- Asked by @gogopotter90. As @erik_jan replied, MicroStation DGN is a format that doesn't support attributes. But there are a couple of methods by which information can be "shoe-horned" in to the data. The first is through a format attribute called an MSLink, which is a join key for a database record. The second is through a feature called Tags, which is a fairly basic method of storing information. Both options can be applied through the parameters dialog when adding a reader:
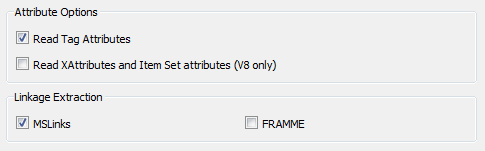
- How to expose attributes with the SQLExecutor
- @eva218 wanted to know how to get attributes out of the SQLExecutor results, when the attribute being selected is itself an attribute value. The solution - as provided by @ebygomm - is to put an "as" command in the SQL, to define the attribute to return, as in:
- SELECT '@Value(AttributeStoringFieldName)' as AttributeToHoldResult from MyTable... etc
- @eva218 wanted to know how to get attributes out of the SQLExecutor results, when the attribute being selected is itself an attribute value. The solution - as provided by @ebygomm - is to put an "as" command in the SQL, to define the attribute to return, as in:
- Unable to interpret error message
- A reminder that you really shouldn't have LOG DEBUG turned on by default, only when you have an existing issue that you are trying to track down. It will only return "false positives" that are really developer log messages, not actual errors.
- How to identify non title case in attributes
- I'd love to know the project @tomjerry.vl is working on (do you have plans to present it at the world tour?) because it seems so interesting. Here the issue is how to identify values like "Venilla road" where the "r" in road should be upper case. The "official" solution is probably to use the AttributeValidator to test the case, but inserting a FullTitleCase function in a Tester works (without affecting the source data), as does a search using a regular expression.
- Calculating hours as a percentage of the day
- A datetime question automatically gets my attention, particularly when I haven't seen it before, like this one by @saint_uk. The question is, what percentage of the working day (7 hours) is a vehicle used (4 hours, 20 minutes)? What's interesting is that most of the time you use FME datetime transformers on a specific datetime, but you can use them on a general question of time by assuming the working day goes from midnight (000000) to 7am (070000). Here's my solution:
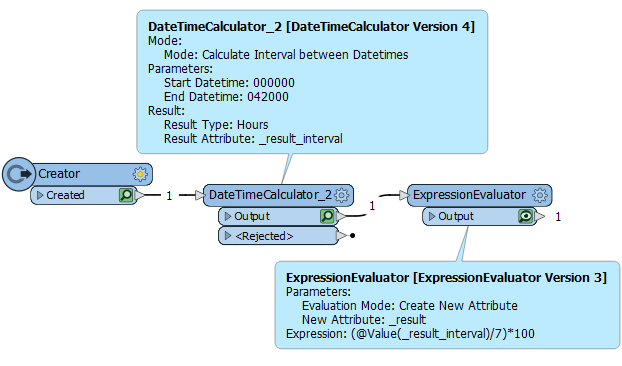
- Basically I tell the DateTimeCalculator to figure out how many hours it is between zero hour and the time used, returning a results as fractional hours. The result is 4.33333. Now I just find the percentage using (4.33333/7)*100. The result is that 4 hours 20 minutes is 61.9% of the working day. The user just needs to format their input into a time past "midnight".
- Creating a polygon from an api response
- As @jdh notes, if your response isn't standard geojson, but json with geometry embedded within it, you'll probably need to use JSON transformers to get the information out.