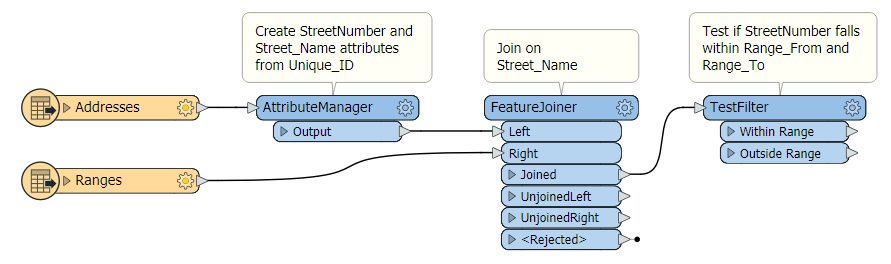
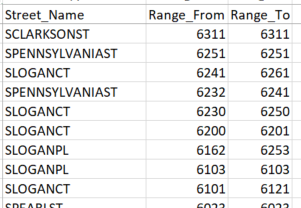
Here's an example of the ranges:
 And I want to check my own point addresses to see if they're outside of the ranges.
And I want to check my own point addresses to see if they're outside of the ranges.
 I've looked at the AttributeRangeFliter, but you have to plug in your own MinMax. Any ideas on where to start? I'm thinking the tester or test filter would work, but I'm trying to plug in mix/max from a table and it's treating it as a row.
I've looked at the AttributeRangeFliter, but you have to plug in your own MinMax. Any ideas on where to start? I'm thinking the tester or test filter would work, but I'm trying to plug in mix/max from a table and it's treating it as a row.
Edit: Now I'm thinking I can just join the ranges and the addresses based on the street name. They're formatted the same so why not? 
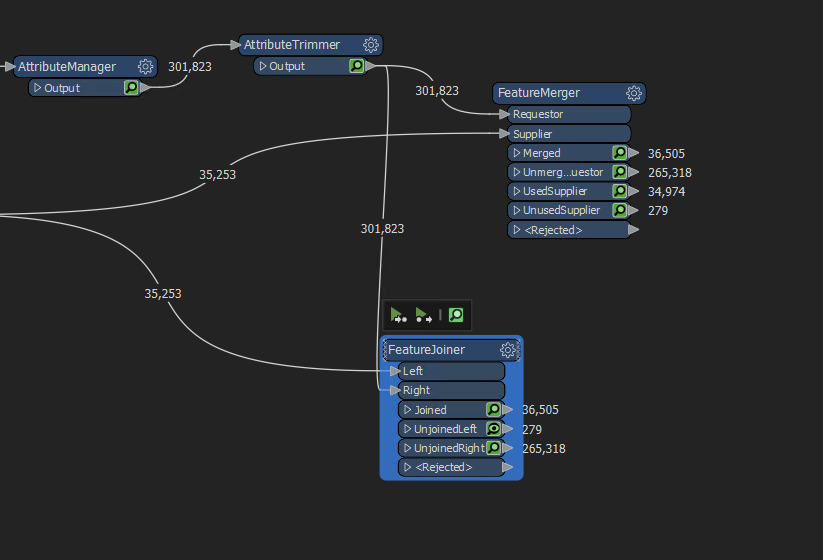
 I have 39k Points and 2300 ranges. When I join based on street names i get 236k rows!
I have 39k Points and 2300 ranges. When I join based on street names i get 236k rows!
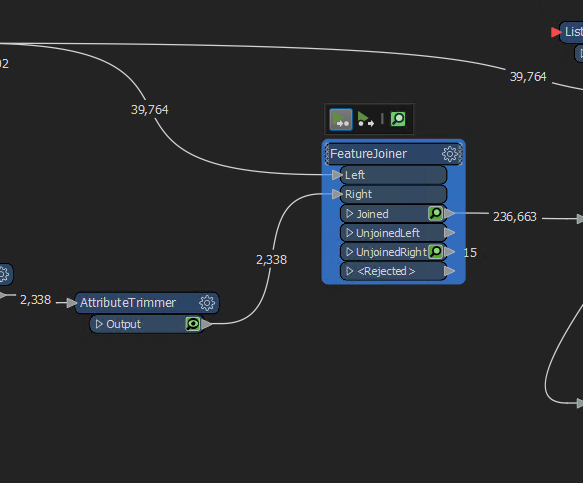 My idea is to join the streets then just run it through a 'in range' in the tester. When i do that I have duplicates for some reason. I'm all confused!
My idea is to join the streets then just run it through a 'in range' in the tester. When i do that I have duplicates for some reason. I'm all confused!
EDIT 2:
So i ran that through the test filter with these parameters: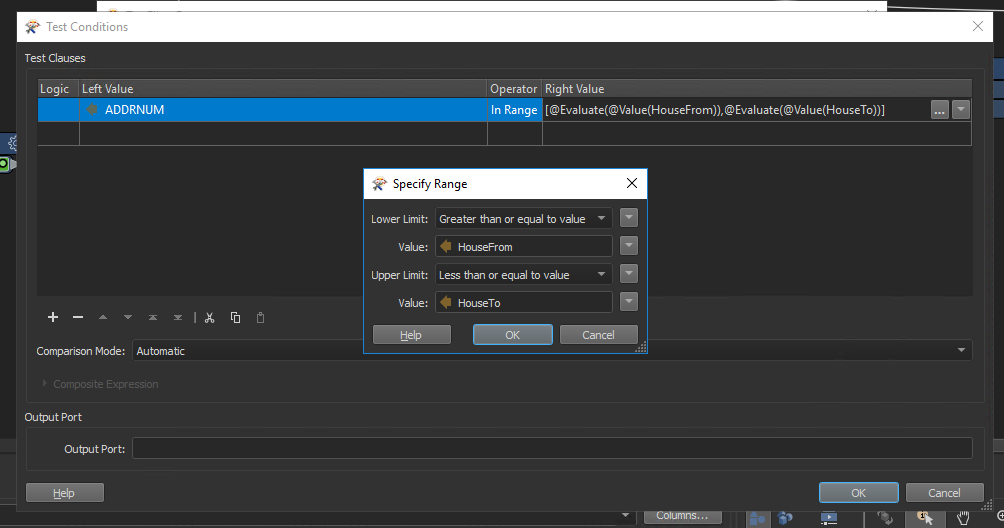 It's kicking back 41,084 records that match that. Do I need to group by or filter them down further?
It's kicking back 41,084 records that match that. Do I need to group by or filter them down further?
EDIT 3:
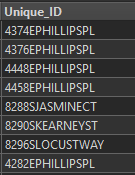
After looking at the data a little more its starting to make more sense, but leaving me more questions. In this screenshot I'm showing the joins on the ranges on E Phillips Pl. Since there are 8 different ranges it's showing 8 records for each address (it's why there are 236k records. I think I need to make a subset of the ranges to compare each one back to?
 Here is a python script for the logic on it. I think it needs to be put into a list or subset of the data to search against the address number.
Here is a python script for the logic on it. I think it needs to be put into a list or subset of the data to search against the address number.
import arcpy
import csv
#PARAMETERS
address_range_csv = 'path' #path to address range csv file
add_pts = 'path' #path to subest of SiteAddressPoint feature class
#SCRIPT
#build range list from csv
print('Building range list from CSV')
with open(address_range_csv, 'r') as file:
reader = csv.reader(file)
range_list = list(reader)
#check if address points are within address ranges
print('Checking if address points are within address ranges')
for row in arcpy.da.SearchCursor(add_pts, ['Unique_ID', 'ADDRNUM', 'FULLNAME']):
#set parameters
unq_id = row[0]
addr_num = row[1]
street = row[2]
match = False
#get subset of address ranges that are on same street as address point
range_subset = [i for i in range_list if i[0] == street]
#check if address point is within each address range in subset
for r in range_subset:
range_min = r[1]
range_max = r[2]
if addr_num >= range_min and addr_num <= range_max:
match == True
#print address point IDs that don't fall in an address range
if match == False:
print(unq_id)
Any thoughts after seeing the code?