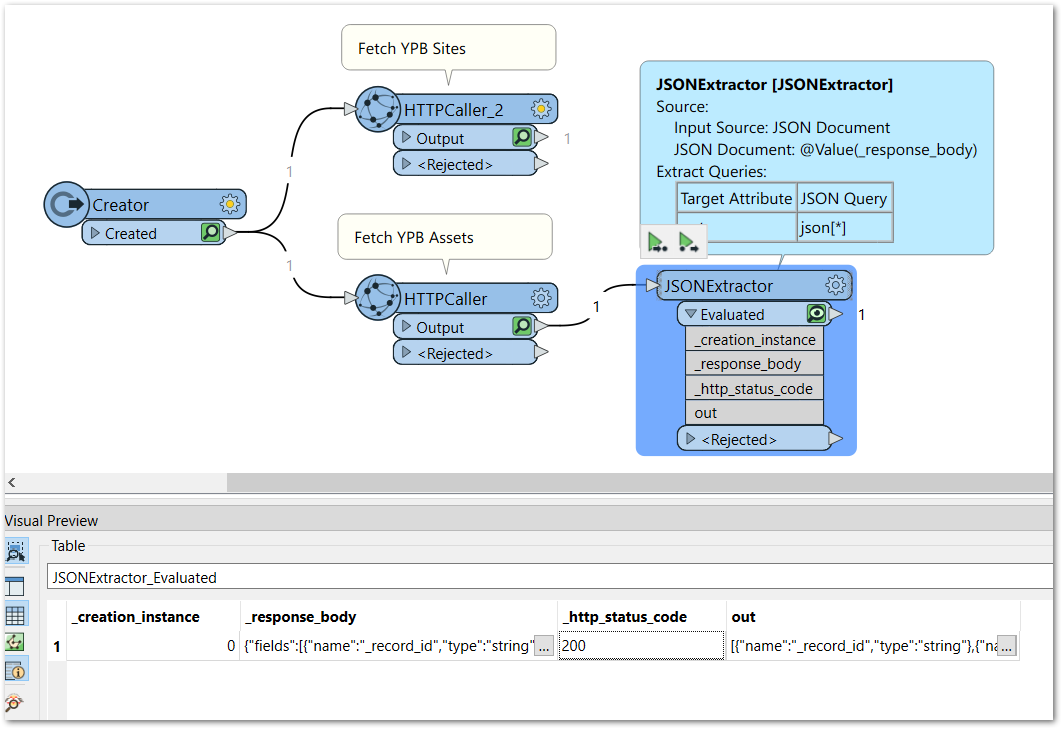
The Reading JSON tutorial demonstrates using Feature Reader to fetch and parse data from a bare url. However I need to fetch from a url that requires a token in the http header. I've used HTTPCaller transformer to do this successfully and I have json data in `_response_body`. However when I feed response body to FeatureReader it treats that as a *path* and not *content*. (It took me hours to figure out this what the error message meant).
How do I read the `_response_body` from the http call as *content*?
https://community.safe.com/s/article/json-reader-configuration