

Hi everyone,
I am new to FME, please help me with the following issue. I am reading an excel file using FME. The name of the attributes (columns) is not right, and its in row 5 of the file. I was wondering how I can assign values in that row (5) as attribute names. I know that I can use a tool like AttributeManager to rename the attributes, but its too many attributes/columns (>100). I need a way that could assign the values from row to attribute name.
Thanks



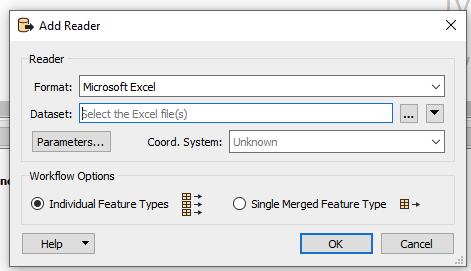 select your dataset then click parameters, and in the Sheets to Read box (at the top) you'll see there is an option to specify what row the field names are in and what row the data starts in
select your dataset then click parameters, and in the Sheets to Read box (at the top) you'll see there is an option to specify what row the field names are in and what row the data starts in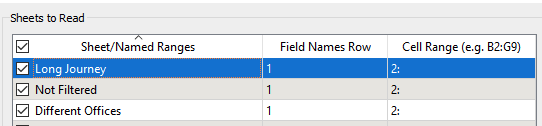 In your case, Field Names Row will be 5 and Cell Range will be 6:
In your case, Field Names Row will be 5 and Cell Range will be 6: