



Hi,
I would like to create a table showing all the attributes available per feature type and the count for each one.
For example, I have these datasets: Trails, Activities, Landscape which contain similar attributes, but also different attributes. (similar = objectid, name...) (different= trail size, type activity).
I want to generate an overview with all the attributes and to which feature type they belong to.
Any idea how I can do that without using too many transformers?
I have already tried many options:
1) attribute exploder, unique values (but then I can trace back to whcih feature type it belongs to)
2) attribute manager, change values to feature type, then statistic calculator (but then I have to use one attribute mananger per feature type which is redundent).
Any ideas how I can make this script dynamic?
Thanks






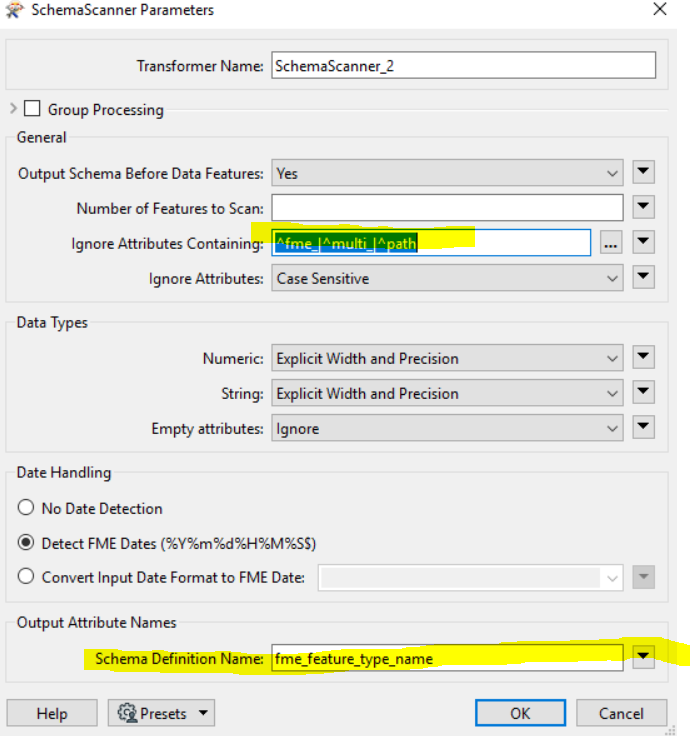
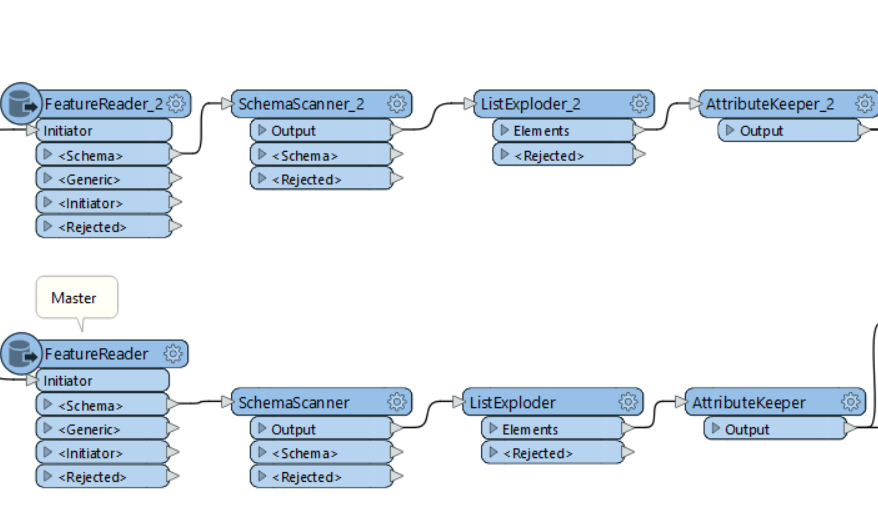
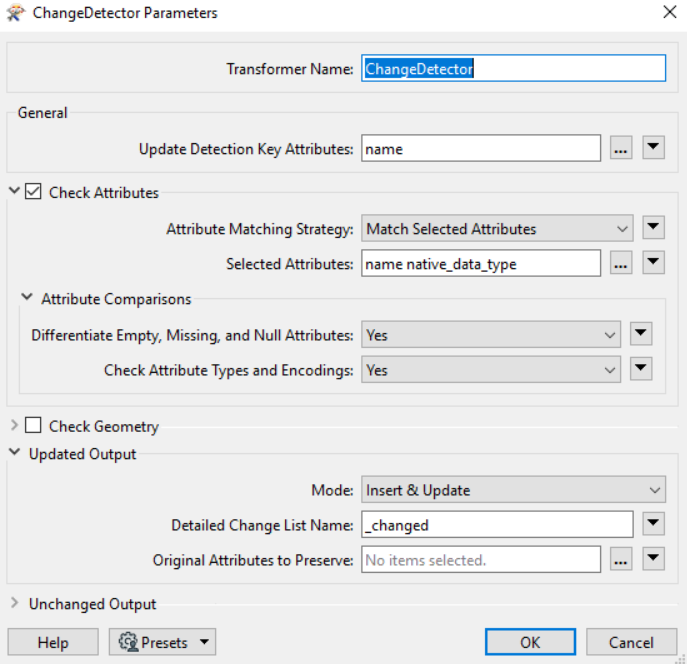
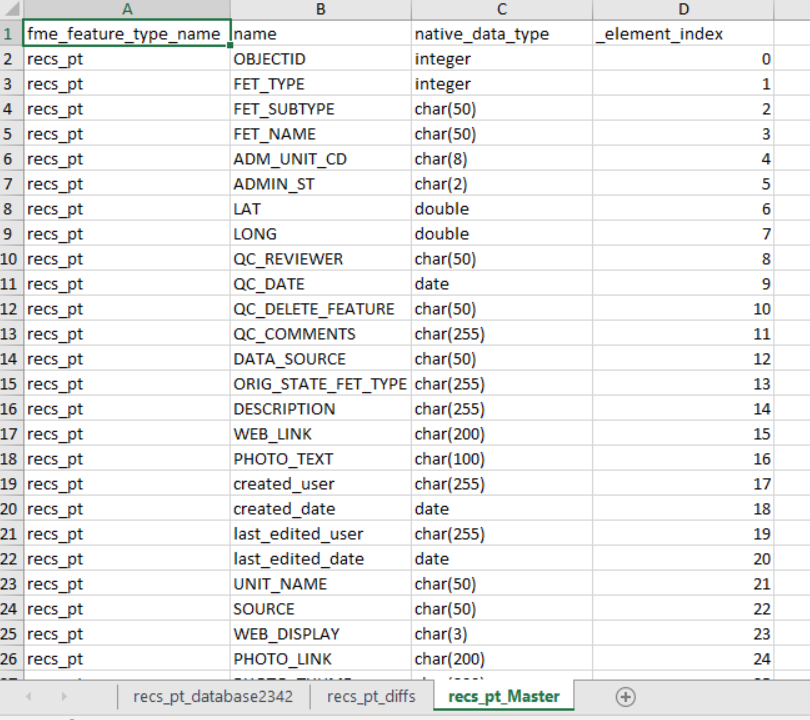 I later added in a couple more user parameters to allow the workbench to be automated (dynamic) through python (advanced):
I later added in a couple more user parameters to allow the workbench to be automated (dynamic) through python (advanced):