

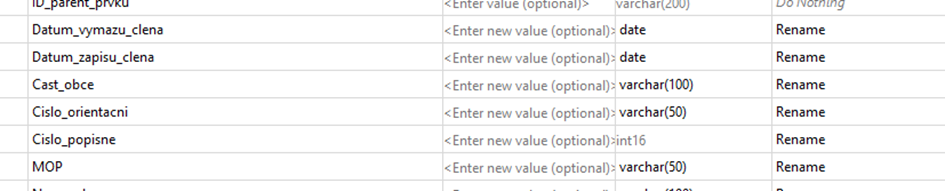
I want to write to an existing FGDB and I'm getting "Esri Geodatabase Writer: XXX attribute value(s) were truncated" (in my case: XXX = 500+) in my translation log. Concerning the attribute values that should get written and given data types, everything seems to be fine. What could be a way to determine which attribute values are truncated and why? I can't find further information on this.

Question
Further investigation after getting "Esri Geodatabase Writer: XXX attribute value(s) were truncated" in log








")



")


Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.