


Hi,
How can I to extract Layer and CODIGO attributes from file below:
<html xmlns:fo="http://www.w3.org/1999/XSL/Format" xmlns:msxsl="urn:schemas-microsoft-com:xslt">
<head>
<META http-equiv="Content-Type" content="text/html">
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
</head>
<body style="margin:0px 0px 0px 0px;overflow:auto;background:#FFFFFF;">
<table style="font-family:Arial.Verdana.Times;font-size:12px;text-align:left;width:100%;border-collapse:collapse;padding:3px 3px 3px 3px">
<tr style="text-align:center;font-weight:bold;background:#9CBCE2">
<td>232400481803401</td>
</tr>
<tr>
<td>
<table style="font-family:Arial.Verdana.Times;font-size:12px;text-align:left;width:100%;border-spacing:0px; padding:3px 3px 3px 3px">
<tr>
<td>Layer</td>
<td>232400481803401</td>
</tr>
<tr bgcolor="#D4E4F3">
<td>CODIGO</td>
<td>48</td>
</tr>
</table>
</td>
</tr>
</table>
</body>
</html>
Thank´s
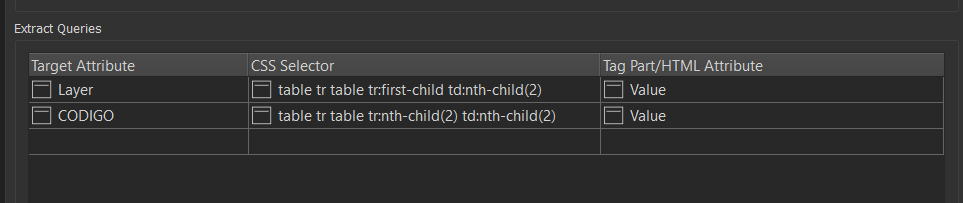 But i'm not sure i'd trust it personally.
But i'm not sure i'd trust it personally.

