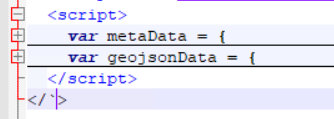
I have two variables within a script tag in the head of an html document.
What's the best way to extract those two variables?
Both variables are json data.
In the end I want the geojsondata and I want to add the metadata to the geojson data.
I can extract the strings for the variables using regex, but is there something better to read javascript?