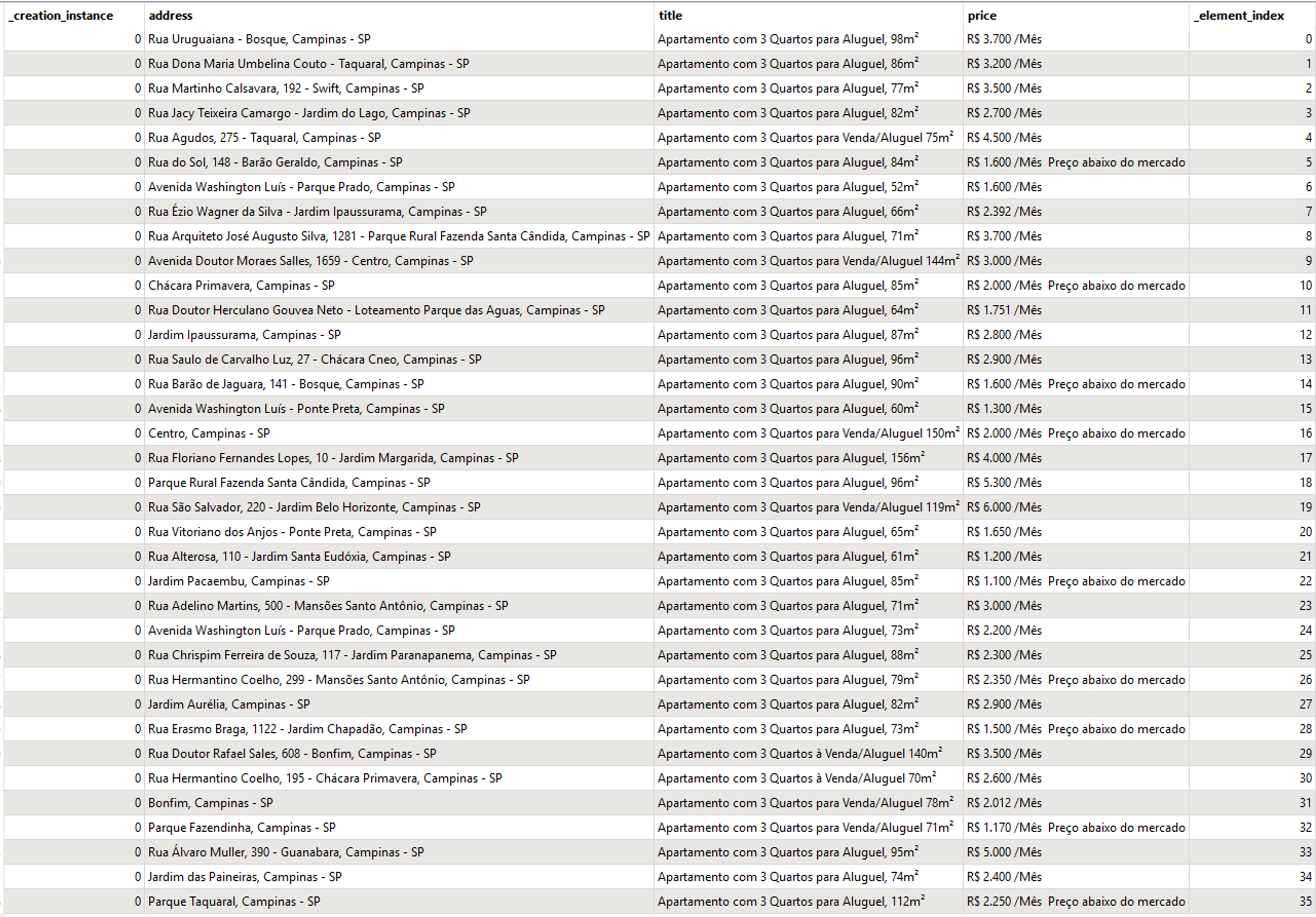
Hi,
In the workspace below, search the website and return many rows.
It´s possible to see in the Translation log, but in the result, only the last row is shown.
How can I receive all rows in the result?
Thank´s

 +9
+9Hi,
In the workspace below, search the website and return many rows.
It´s possible to see in the Translation log, but in the result, only the last row is shown.
How can I receive all rows in the result?
Thank´s
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
")

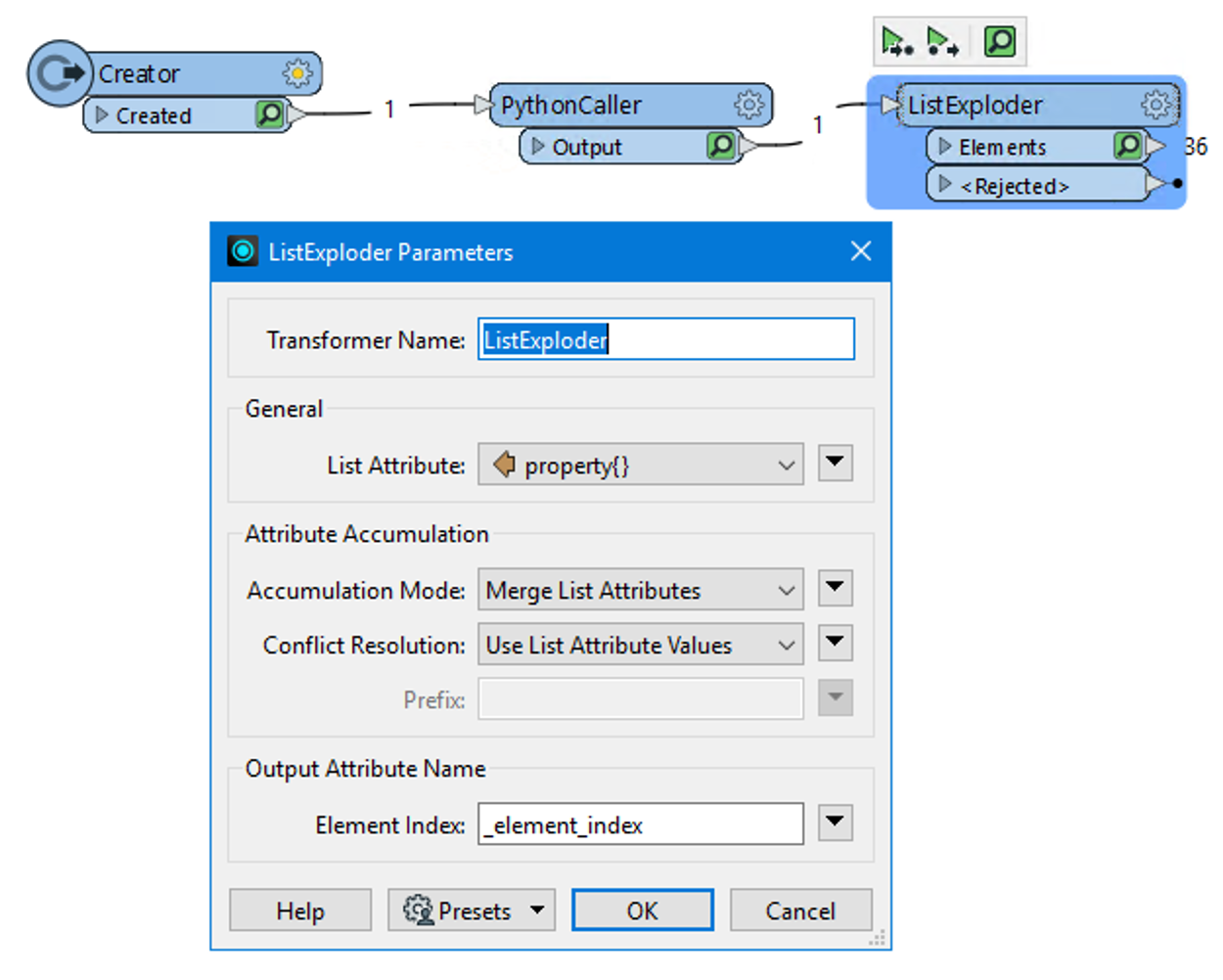 Result:
Result: