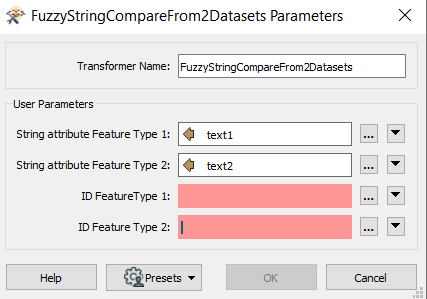
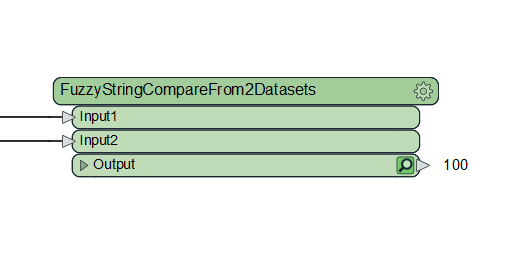
Hello there I have a 20K features each feature has an attribute with Long text content each text with diffirent word count , we need to compare features to each other and extract the text features that have similarity ,
Any way to do this with FME
Thanks