I have CSVs with over 2 million rows. For some reasons, Reader appears to be dropping some columns , and yet I know Reader recognised they existed because they are missing in the column name order. For example, when columns col3 and col6 are dropped the auto-generated attribute names are col0, col0,col1,col2,col4,col5,col7,col8,col9. I have tried various options in reader but clearly not the right one . There is plenty of RAM and disk space. In some files, the missing columns are blank but I have also seen this happen in files that do not have blanks in missing columns. Some columns have strings enclosed in double-quotes. Any pointers please

Solved
Columns recognised but dropped when reading a CSV file
Best answer by ebygomm
This occurs if Scan for Types is set to Yes (I'm not sure if 2020 now defaults to this behaviour). It doesn't look like the desired outcome of this setting in any case, as it's not just skipping columns but putting some data in the wrong place and losing other bits
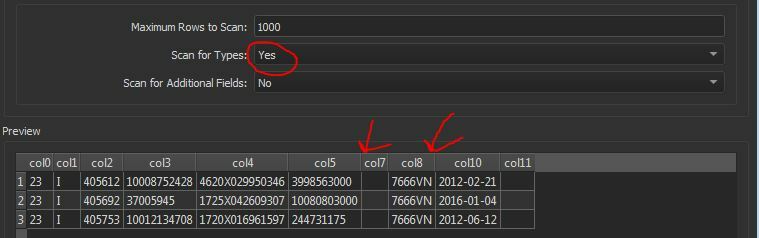
Changing Scan for Types to No reads all the columns correctly.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.






Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.