
I'm reading a number of json files each with their own set of records. I can see I need to expose many attributes but without adding hundreds of lines (the index goes to 142). Is there any easy way to go from screengrab below to web site structure at http://reg.bom.gov.au/products/IDT60801/IDT60801.94850.shtml: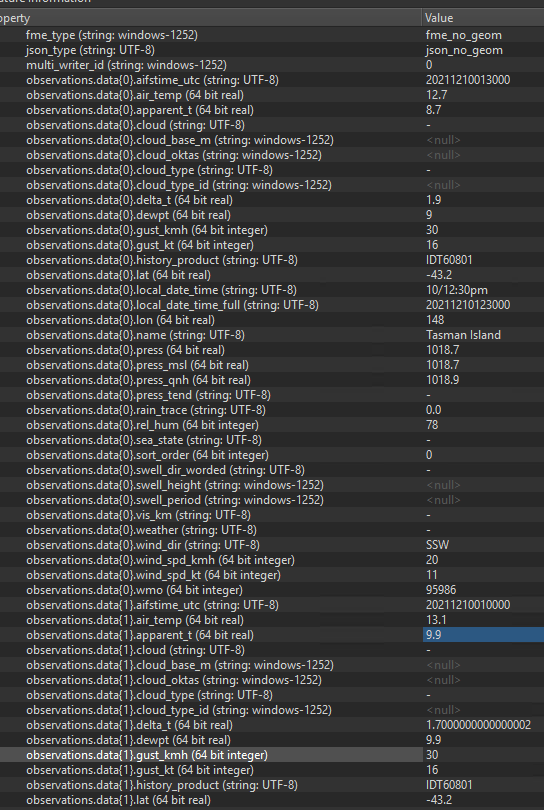

Solved
Attribute Exposer many fields?
Best answer by hkingsbury
have a look at the attached. Makes use of the JSONFragmenter to both read the JSON and break it down
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.











Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.