



I have a bit of a dilemma. I'm setting up a self-serve workflow where the end-user will have to upload some files and then run them through a validation and processing workspace.
The files that are needed are 1 mid/mif and 5 csv's with different schema's. To make things easier I want the user to zip them all up and upload them as a single file. I'm using a File user parameter then point that to a Generic reader which reads [somethingsomething].zip\\*.* and then use wildcards to match them to the specific feature types. This works fine if a single zip file is processed.
However... this data is grouped by region and the customer indicated that sometimes they need multiple regions. Plus... features from two adjacent regions may actually geographically coincide, so the processing workspace needs to have them both at the same time.
I set up the File parameter to handle multiple files as input, split the value and then run them through a FeatureReader. That's where the issue is: I can't seem to get it to recognize the separate csv's, they're all lumped into one port and I'm not even sure it's reading all the attributes from all 5 csv's.
Any ideas? I really don't want to go to adding separate readers for everything because of the high potential for user error.



 The csv's all have a different schema (and it's important, because there's a lot of logic happening) and their names *may* be prefixed, although I think we can make a good case to not allow that. I also want to keep it as simple for user as possible, so only a single upload.
The csv's all have a different schema (and it's important, because there's a lot of logic happening) and their names *may* be prefixed, although I think we can make a good case to not allow that. I also want to keep it as simple for user as possible, so only a single upload.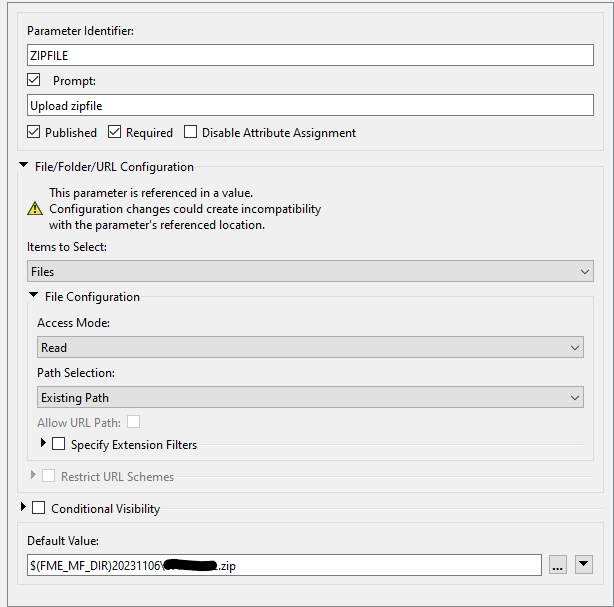 Which then gets put into a Generic reader:
Which then gets put into a Generic reader: The \\* is to force the Generic reader to look inside the zipfile. I've added a CSV reader as a resource and imported the feature types, using wildcard matching to make sure the right data ends up in the right place.
The \\* is to force the Generic reader to look inside the zipfile. I've added a CSV reader as a resource and imported the feature types, using wildcard matching to make sure the right data ends up in the right place.

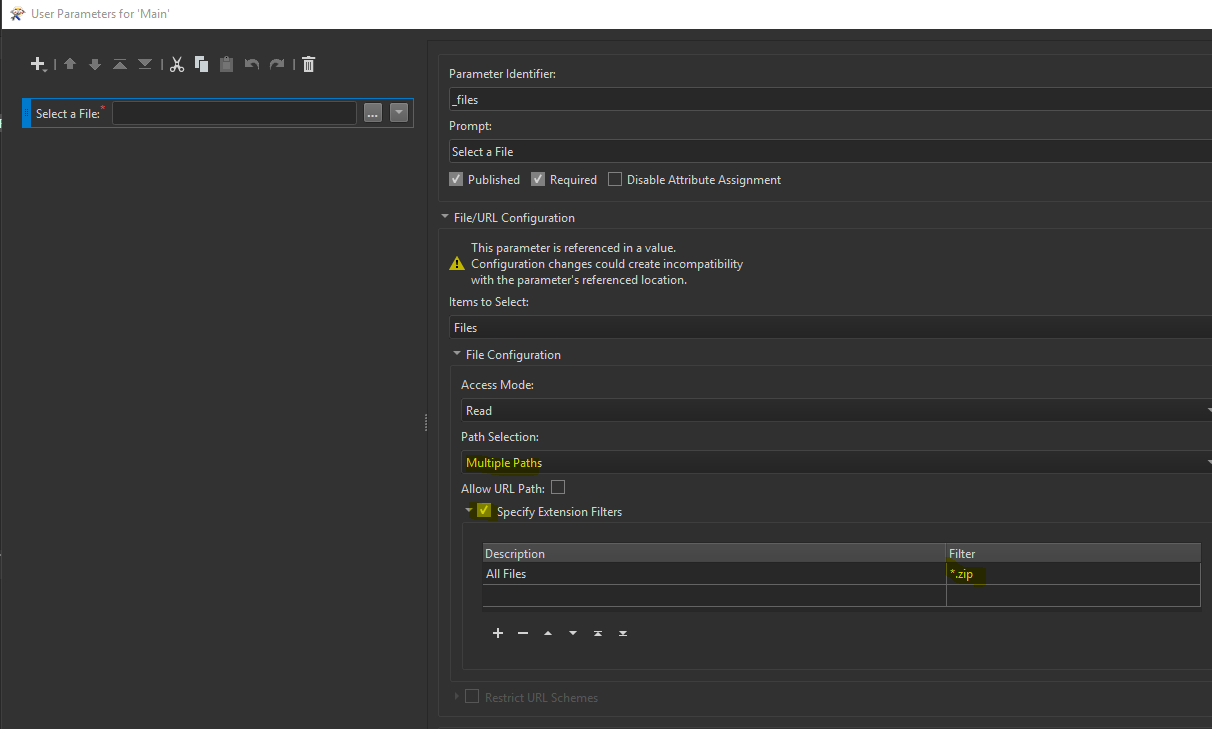 (however if leave it as * and in the feature reader have it read recurse subfolder should achieve the same thing) so I don't think that was the issue.
(however if leave it as * and in the feature reader have it read recurse subfolder should achieve the same thing) so I don't think that was the issue.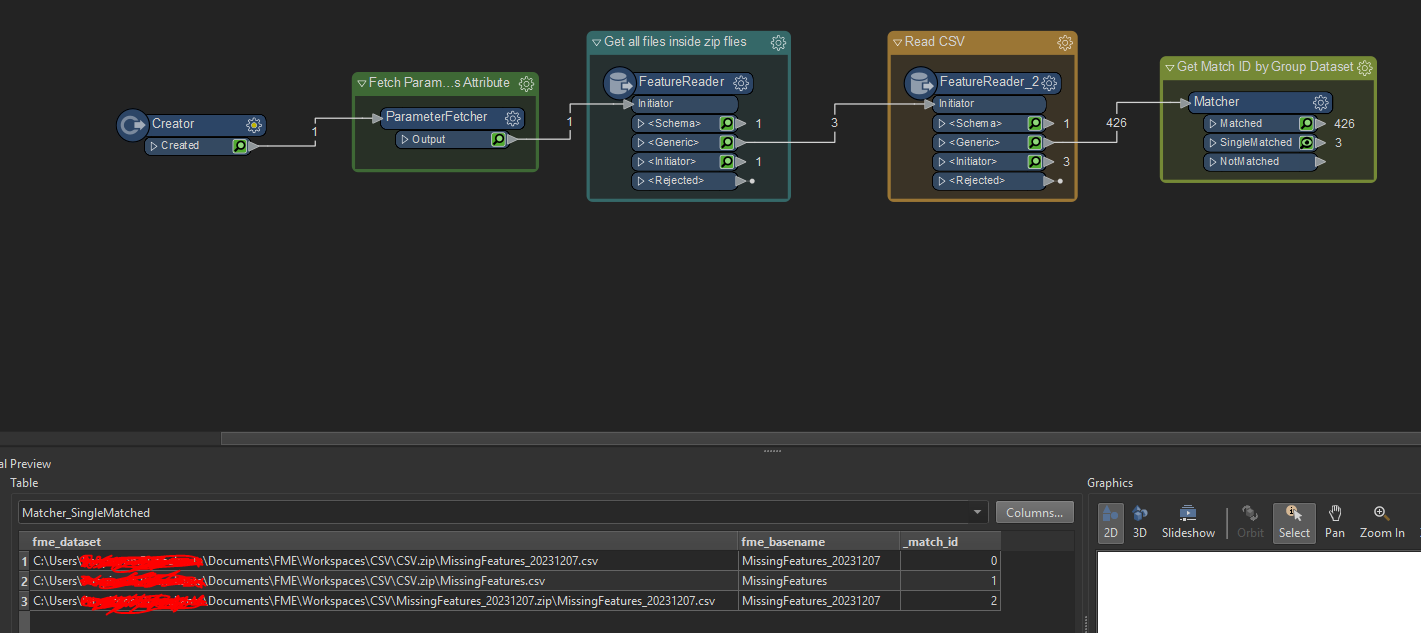 I also attached the workspace to see if this would work.
I also attached the workspace to see if this would work.