



Our fme cloud export has been going wrong for about 2 months.
Every other week we import gml-files into a Postgress database.
The export from our Postgress database gives errors in a small part (16 of 235) of our export files in the formats csv and shape.
Only the BGT_WGL_*.shp/shx/prj/dbf and BGT_WGL_*.csv files fail. The fme scripts have not been changed in recent years.
When we run the fme script locally (fme2019) on a PC the export of these files gives no errors.
Has anything changed in the "FME cloud" environment lately? In some of the transformers?
Last Friday (sept 16) we did a reboot of the FME-cloud environment but this did not help.
Attached are some examples of a shape and csv file which look like an error file in html format.
Also, we can't find any log files in the cloud of the fme creation process of the shape and csv files.
These log files (which we do have locally) can help us on our way solving the problem.
We also did not receive an error message that it was not possible to export a good shape/csv file.
Our cloud: https://vicrea-amsterdam-2016.fmecloud.safe.com/instances/



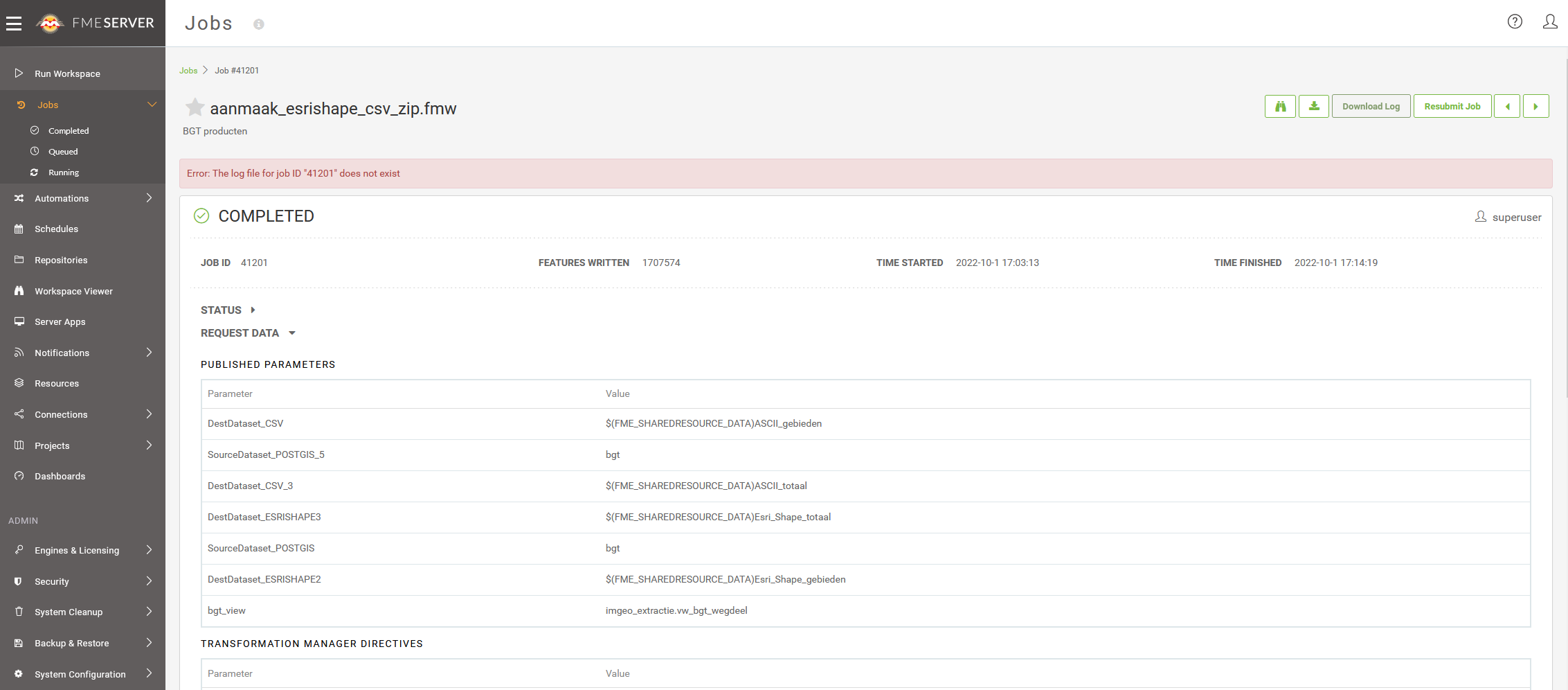 Forgot the screencopy 😁 ....
Forgot the screencopy 😁 ....


