


I'm using a HTTP caller to download a ZIP file from a API. After that I'm using the ZipExtractor transformer to extract a number of csv files from the ZIP file to a folder and then a FeatureReader reads the files and so on. Only problem I'm having is that the CSV files change from time to time. They all start with the time of the export followed by the filename. So every time that happends I have to go back to the FeatureReader, select the files again and reconnect the files to their appropriatie transformers.
Is there a way to rename the files after the ZipExtractor ? I have found some topics using the Directory and File Pathnames Reader with the File Copy writer but I cannot get that to work. Any help would be greatly appreciated.



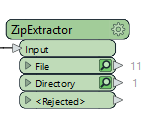 When I connect the FeatureReader to the File output, select CSV file and the path_windows attribute for the dataset I get a popup asking me the following:
When I connect the FeatureReader to the File output, select CSV file and the path_windows attribute for the dataset I get a popup asking me the following: 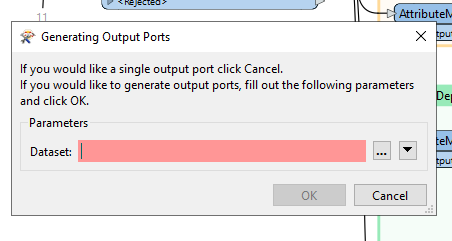 When selecting the three dots on the right an Explorer window opens up where I can select a file. Since I don't want to have to select the file manually I hit cancel. After running the FeatureReader I connect a AttributeExposer and import from feature cache. However, since a lot of csv files share the same attribute names the list is incomplete and has a lot of missing values. Now I can do a single FeatureReader per file but is there a faster way then that?
When selecting the three dots on the right an Explorer window opens up where I can select a file. Since I don't want to have to select the file manually I hit cancel. After running the FeatureReader I connect a AttributeExposer and import from feature cache. However, since a lot of csv files share the same attribute names the list is incomplete and has a lot of missing values. Now I can do a single FeatureReader per file but is there a faster way then that?