Hi @bbbutler ,
The XML tutorial Trent posted is a good place to start. Unfortunately the source XML you need to read from has a rather highly normalized, complex structure, making it a challenge to work with. Basically it has one metadata element with field names and then a series of row elements with value series that correspond to the field names in the metadata element. So what you end up with is a field name list and then a series of value lists. The problem then isn't so much reading the XML as it is transforming the lists that are read into flat FME features.
incidentxml-to-csv.zip
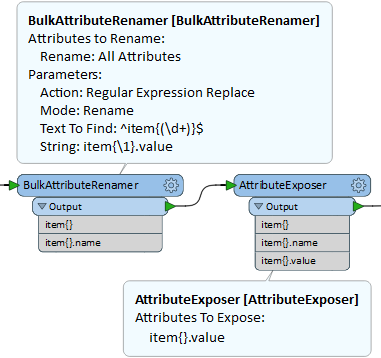
The attached workspace demonstrates 2 approaches. You can just read the row values into one list per feature, then use a ListExploder, AttributeCreator and Aggregator to pivot the list into col0 to col21. Then its a matter of manually mapping this to your destination schema. Or you can use a dynamic schema approach that reads the metadata and value lists, merges them into item{}.name and item{}.value - name / value pairs, and then uses the FeatureBuilder custom transformer from the Hub to generate records from these lists. Unfortunately, at the moment there is some python involved here as FME has limitations when trying to convert between unstructured and structured lists.