Hi,
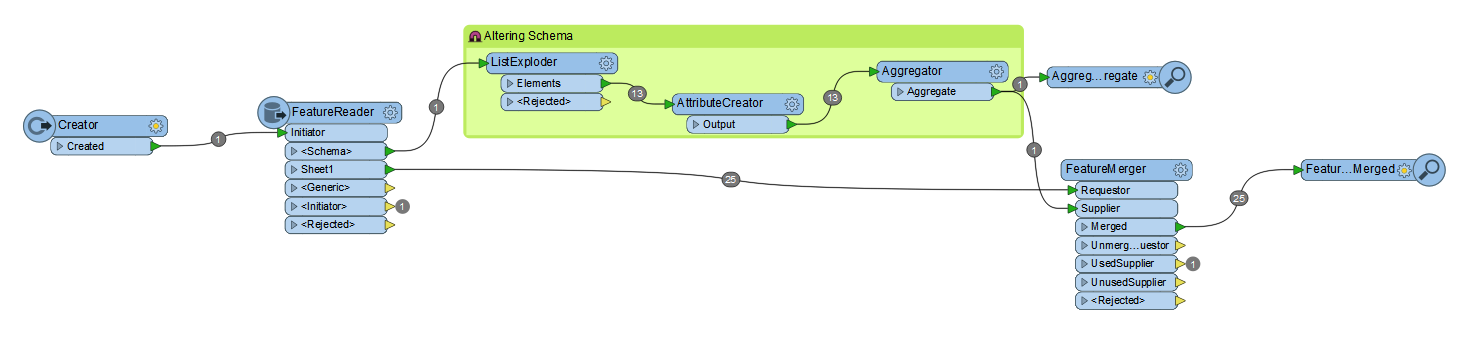
I'm converting excel sheets to gdb feature classes and I'm not sure why but some of the values in my attribute table are different from the actual values in the sheets.
Example images:
This wouldn't be a huge deal except for the fact that the fields with the decimal values are being recognized as text. I have to create new numerical fields and migrate the data using the field calculator and would like to prevent this somehow.
There isn't any formatting in the cells, and when I do migrate the data to a new field, the values revert back to what they are in the excel sheets. I've tried copy/pasting values into a new worksheet and end up with the same thing in my attribute table.
Has anyone seen this before?
Thanks!