I'm removing duplicates from a File Geodatabase (FGDB) feature class using Sorter then DuplicateFilter, then writing the Unique features back to the same FGDB feature class.
I want to write the Duplicate features to a CSV log file with the date/time of the translation in the file name so I have a CSV listing the duplicates removed each time the Workspace is run.
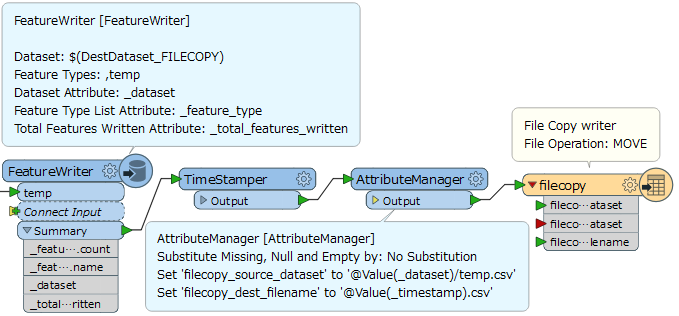
First I tried including @Timestamp(^Y^m^d^H^M^S) in the CSV File Name in the Writer but I ended up with multiple CSVs, presumably because features were being written as they were received by the Writer. I haven't noticed this problem with FGDBs but is that because of difference in the way the FGDB Writer works?
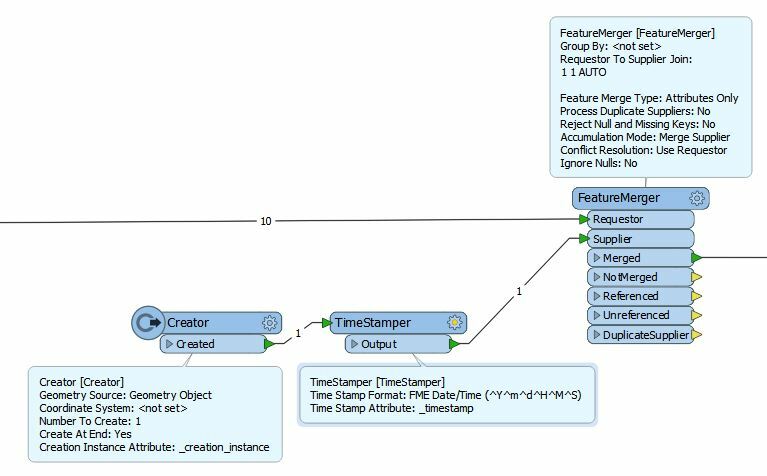
I then tried a Creator followed by a TimeStamper running parallel to the actual data processing with the output from the TimeStamper going to the CSV Writer along with the data. But what I get is two CSV files - one with no date/time stamp in the name and all the data, and another with the date/time stamp in the name but no data.
Would "Append to file" in the CSV Writer properties solve this? If so, how can I ensure that the CSV file with the date/time stamp in the name is created first?