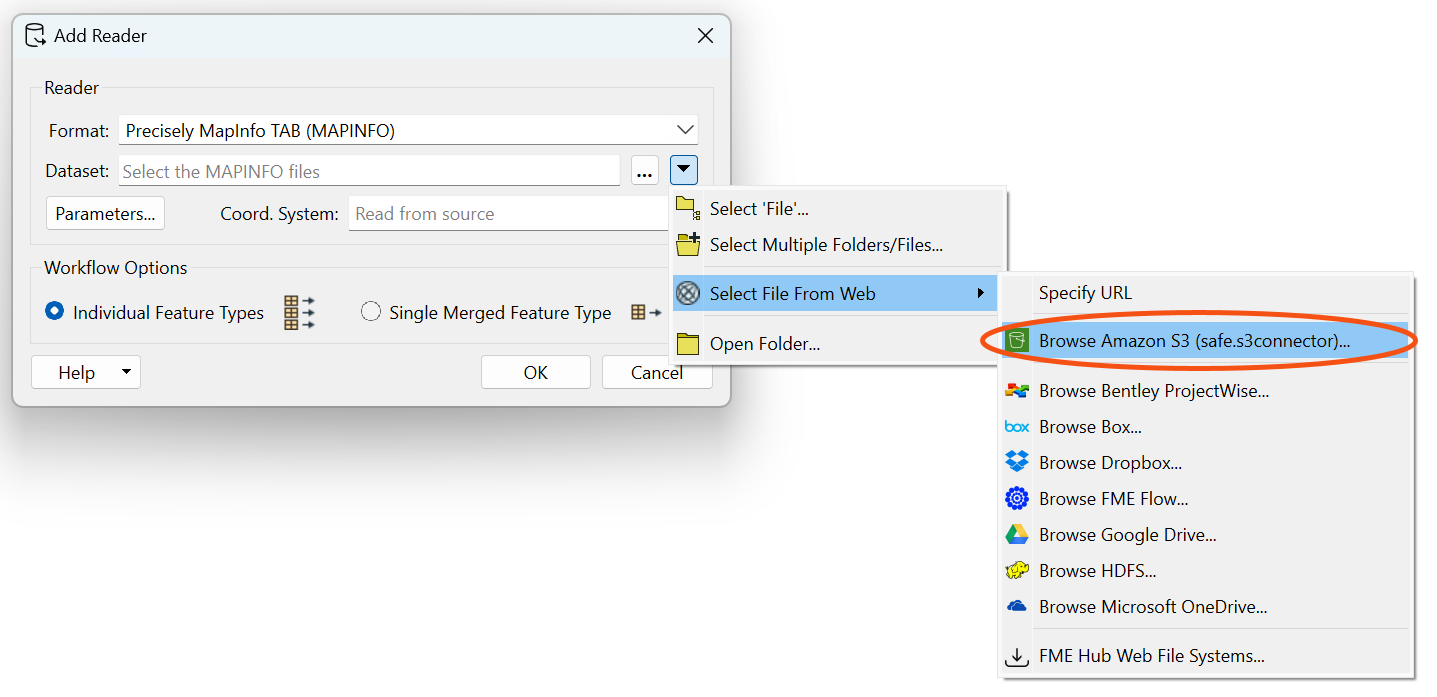
I need to extract TAB or Shape file from S3 and read data from it including schema.
I have discovered in this article
that FeatureReader apparently can’t read all attributes that are in the file, until I expose them. But what is I don’t know the list of all attributes? I don’t know what exactly will be uploaded by other people to S3 bucket, I just need to read the file.
Could you help, please, to identify the correct settings of FeatureReader or another way to extract data?