

Hello,
I am new-ish to FME and primarily used model builder for previous needs which may show in how this model was created.
So I am reading from .sde, changing some field names among other things and outputting the data to both a kmz and to individual shapefiles to a zipped folder. Not all of the feature classes have NFID within their table so I am using this parameter not only for the output file names, but also to select the line with the specified NFID and then buffer to select surrounding features.
I created this to run for one project at a time using a parameter NFID which is basically a project name/number to select the correct data and to name the output folder and kmz file.
I want to expand this further and have it run through ideally a list of NFIDs and ultimately read from a good sheet and run based on those values when project status is updated in the table but that will be the next step once I can get this to reset and run for each NFID entered.
Current Process: input project specific identifier NFID as a user parameter then run the model
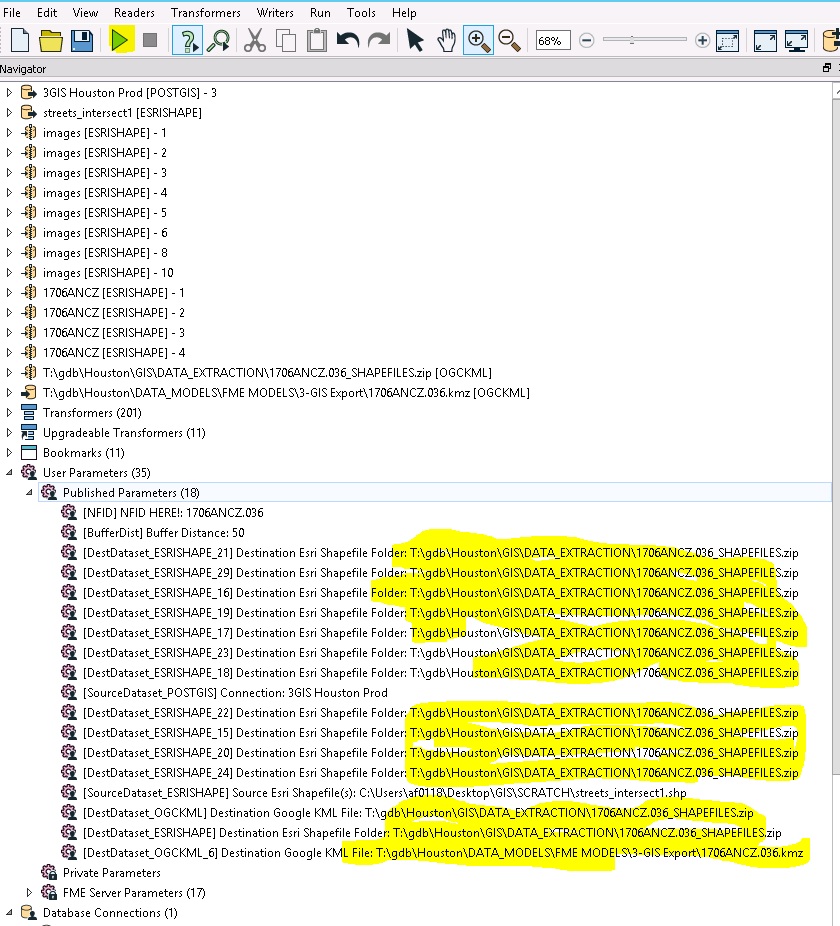
Once the model runs successfully I am undoing the last action to reset the output names:
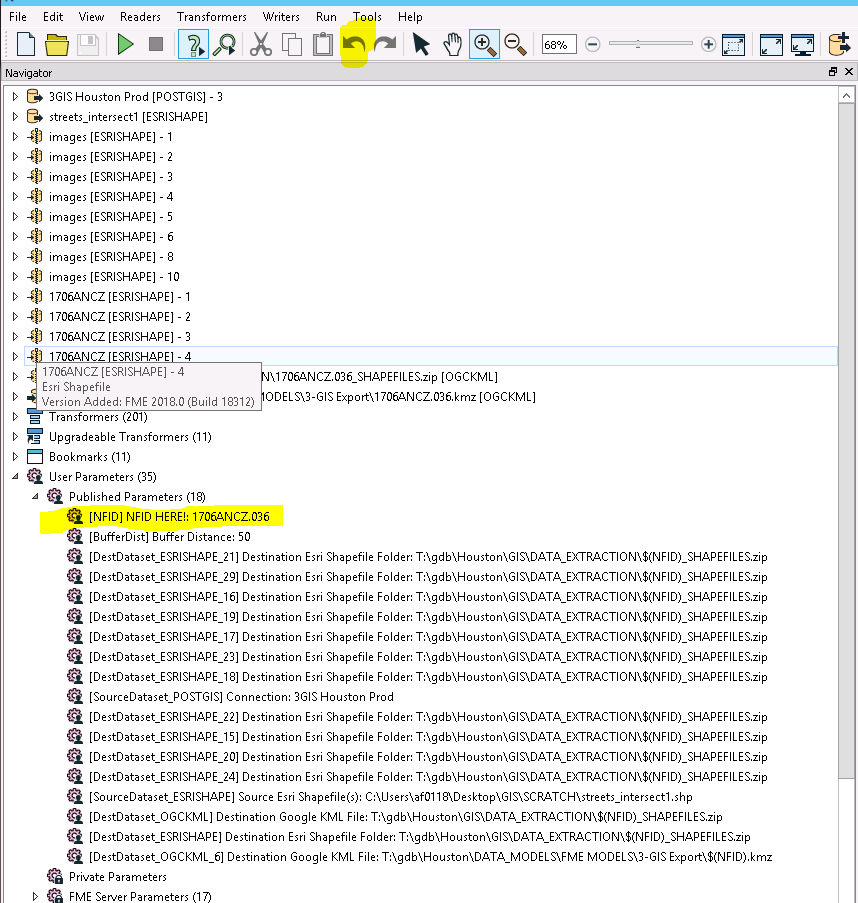
Any ideas on how this can be run for multiple NFID input without recreating this entire model or having to undo last action after running the model?
I would also love any input on how to run this per NFID based on project status in a google sheet.
Thanks!

