

Hi
Situation
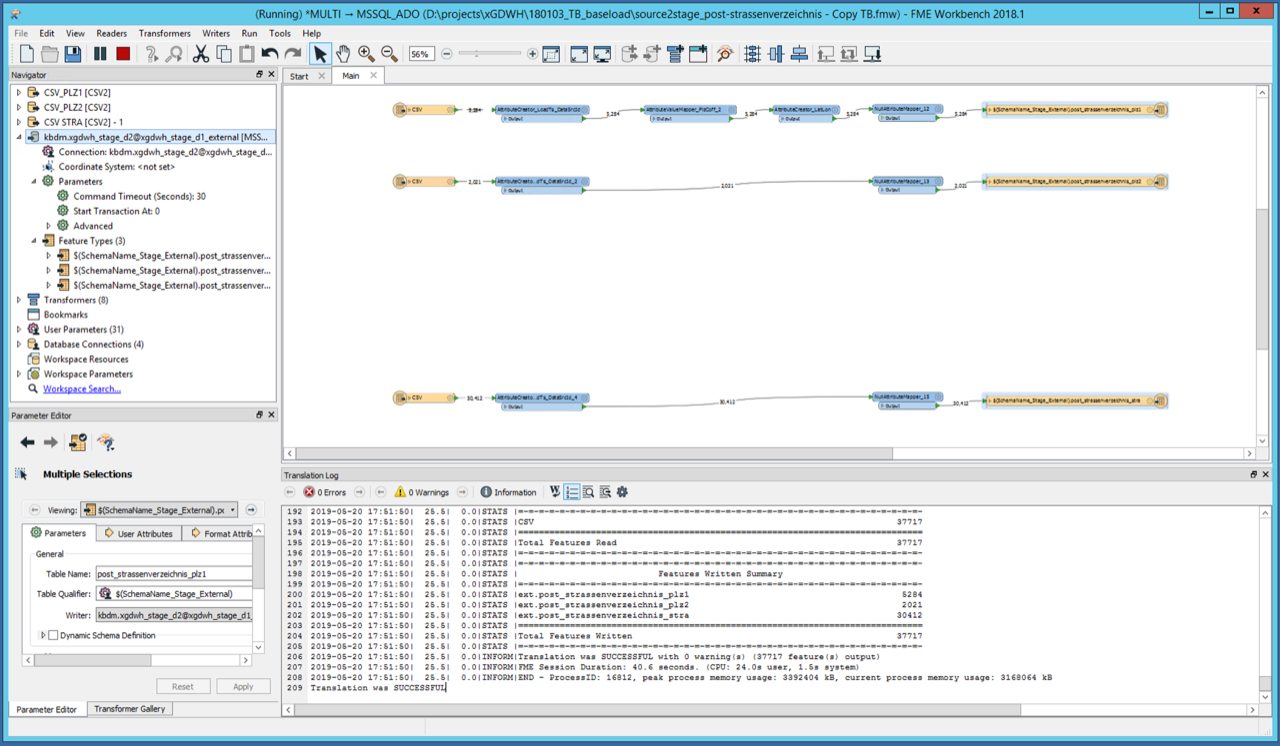
We have a quite simple FME Workbench, loading CSV data from an URL, and writing it's data to a MSSQL database. The workbench works fine, writes all data and terminates with "Translation was successful".
Problem
Sometimes (actually mostly) the workbench doesn't stop right after it logs "Translation was successful", as it's supposed to do. Everything's done, all records have been inserted, but the workbench keeps running. Sometimes it takes 5min or 10min, sometimes it takes days until the workbench stops.
The screenshot shows the situation. In this case it was a time lag of 5 min.
Facts
- FME 2018.1
- MSSQL 2016; it's on the same machine
- With PostgreSQL or Oracle we never experienced the same issue
Any ideas or hints?
Regards, Tobias










