
Hi,
I'm trying to create a dynamic workspace to create file geodatabase extracts of data out of ArcSDE. Ideally, I would like to make use of change detection in some form, so that data that hasn't changed doesn't get processed for no reason. Even more ideally, I'd like to query the database system tables to quickly narrow down what objects have experienced any change (I have some ideas on how to satisfy the second part, but haven't gotten to it yet).
The SDE extracts in FGDB form will end up on a network share and be replicated out to the users.
This article is pretty much what I want to do, I think.
https://knowledge.safe.com/articles/1157/dynamic-workflow-tutorial-destination-schema-as-a.html
I have to presume that I don't know the schema, nor the quality of the data, in an effort to make this flexible for the many SDE databases we're running this for.
My workspace looks like this:
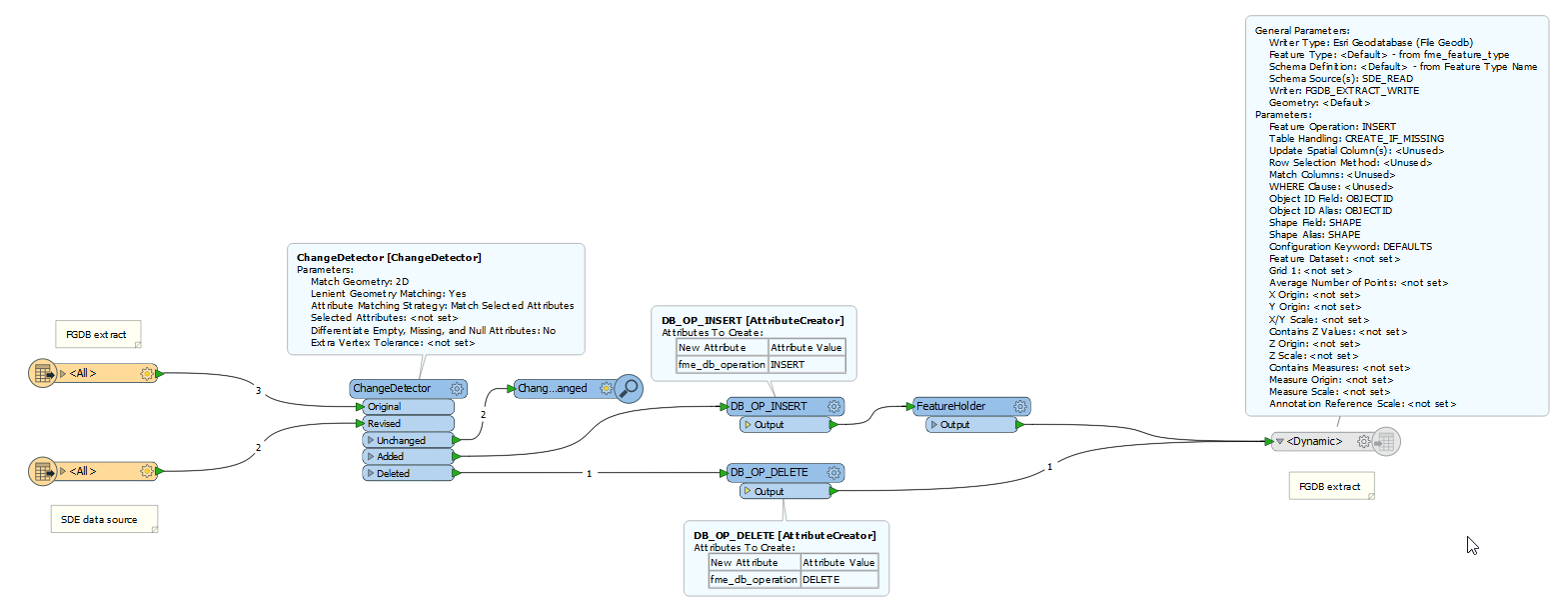
Where I'm getting stuck, right now anyway, is applying the delete operation to rows that no longer exist in SDE. In specifying the fme_db_operation keyword as the 'Feature Operation' method on the writer, I must supply criterion (which is part of the FGDB schema, it seems) so that the right rows are removed. Screenshot:

If the task here is to mirror an SDE database with any number of tables, all with different fields, how can I do this reliably? More frustrating: I have seen an example that uses Esri's Data Interop extension that doesn't seem to be restricted by this requirement, even though it's using the FGDB writer.
Am I missing something obvious here?
Thanks,
Chris


