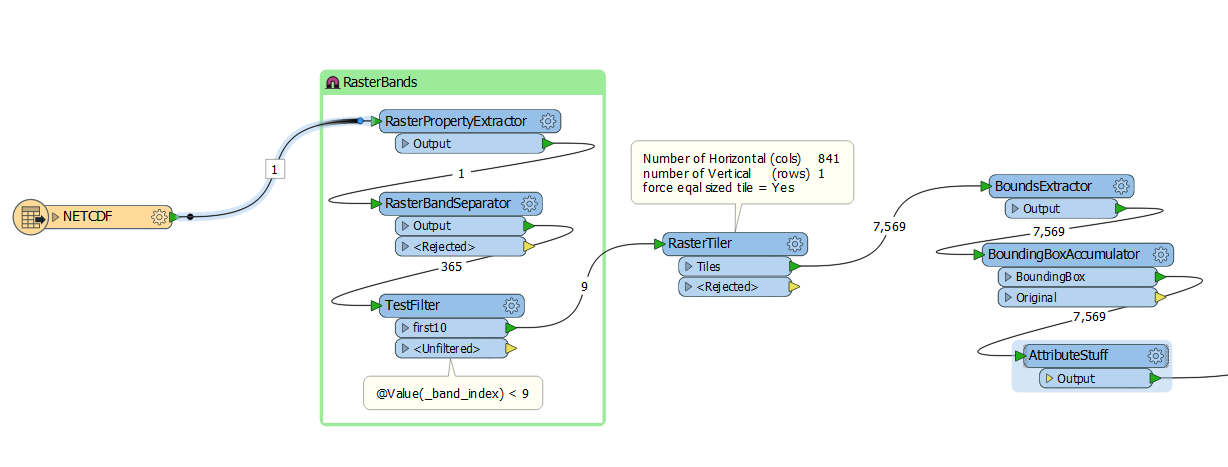
Dear FME-users,
I’m creating feature classes (polygons) from NetCDF-data. Among other things I use the transformer “RasterCellCoercer”, the transformation needs so much time.
I’ve 504 input and 504 output files. The geometry is always the same, just the values of the input data are different.
Do you’ve an idea how to reduce the processing time? Maybe a predefined grid?
Thank you so much and best regards.
Konrad