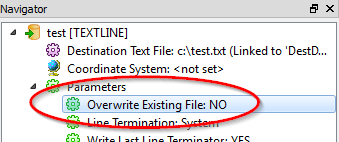
How to copy the contents of a file (File_m.csv) into another file (File_n.txt).
Such that it does not overwrite but only appends to File_n.txt.
File_m.csv File_n.txt output expected: File_n.txt
A B C D E F 3 5 6 2 7 7 A B C D E F
M N O P Q R 8 7 5 0 1 3 M N O P Q R
3 5 6 2 7 7
8 7 5 0 1 3
Regards.