


Hi everyone!
Curious if I could pick your brains on how to achieve the workflow:
I am connecting to an asset via API as well as another separate GIS Feature Class in an EGDB.
The workflow will start with a user editing the GIS Feature Class. When a user updates or creates a new record in the GIS Feature Class, I am pulling it into the Change Detector, and wanting to write to the API table only if the asset_id does not exist in the API table. The asset_id field in the GIS FC = unitid in the API Table, as the field has a different name than the same column has in the GIS Feature class.
Here is how my workspace is looking now, with the top line connecting to my API as the original source in the Change Detector, and my GIS FC as the Revised source in the Change Detector.
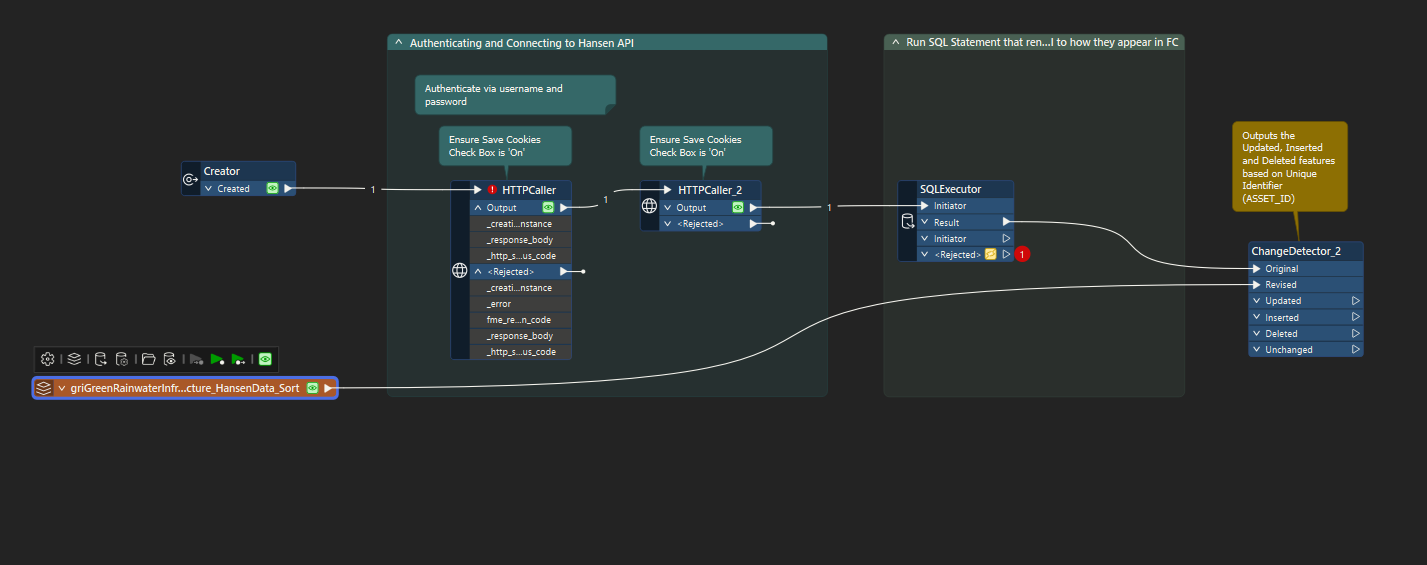
That’s one of the main prediciments here is that the data schemas are different as the original source is a Hansen API table whereby the fields have different schemas/naming conventions than the fields in the GIS FC (by design as requested by the business).
I wrote an SQL statement that I’ve ran in Oracle SQL Developer that successfully renames the fields from the Hansen API table into what is shown in the GIS FC, however I can’t get a transformer to accept the format of SQL in FME.
Attached is my SQL statement that has worked in Oracle SQL Developer:
select
cov.ADDBY AS Added_By,
cov.ADDDTTM AS Added_date,
cov.ASSETKEY AS Asset_Key,
cov.COVDOCSLINK AS Network_Folder_Location,
cov.COVDRAINAREA AS Drain_Area,
cov.COVDRAWFOLDLOC AS Drawing_Folder,
cov.COVDRAWPRES AS Drawing_Present,
cov.COVGIBASINTYPE AS Basin,
cov.COVGILOCTYPE AS Location_Type,
cov.COVGISSHEDTYPE AS Sewershed,
cov.COVGISUBTYPE AS Subtype,
cov.COVIMPERVAREA AS Impervious,
cov.COVMAINTENANCE AS Maintenance,
cov.COVPRACTICESIZE AS Asset_Area,
cov.COVRESERVOIRGIKEY AS Reservoir_GI_Key,
cov.COVVANDOCS AS VanDocs,
cov.ENGINEERINGLIFE AS Engineering_Life,
cov.GISID AS GISID,
cov.MODBY AS Modified_By,
cov.MODDTTM AS Modified_Date,
cov.LOCNOTES AS Notes,
cov.MRN AS MRN,
cov.PLANNEDDECOMMISSIONDATE AS Planned_Decom_Date,
cov.REPLACEMENTVALUE AS Replacement_Value,
cov.SUBCLASS AS Subclass,
cov.YEARCONS AS Year_Constructed,
comp.ADDRKEY AS Address_Key,
comp.AREA AS Local_Area,
comp.COMPKEY AS Compkey,
comp.OWN AS Owned_By,
comp.SEGKEY AS Segment_Key,
comp.SERVSTAT AS Status,
comp.UNITDESC AS Address_Description,
comp.UNITTYPE AS Typology,
comp.UNITID AS Asset_ID,
comp.WATCOURSE AS Watershed,
comp.XCOORD AS Longitude,
comp.YCOORD AS Latitude,
comp.CONSTRUCTEDBYCONTRACTOR AS Constructed_By,
comp.DESIGNEDBYCONTRACTOR AS Designed_By
from
am_reservoir.covreservoirgi cov,
assetmanagement_reservoir.compres comp
where
cov.assetkey = comp.compkey;
That being said, I get this error when plugging the same into the SQLExecutor Transformer.
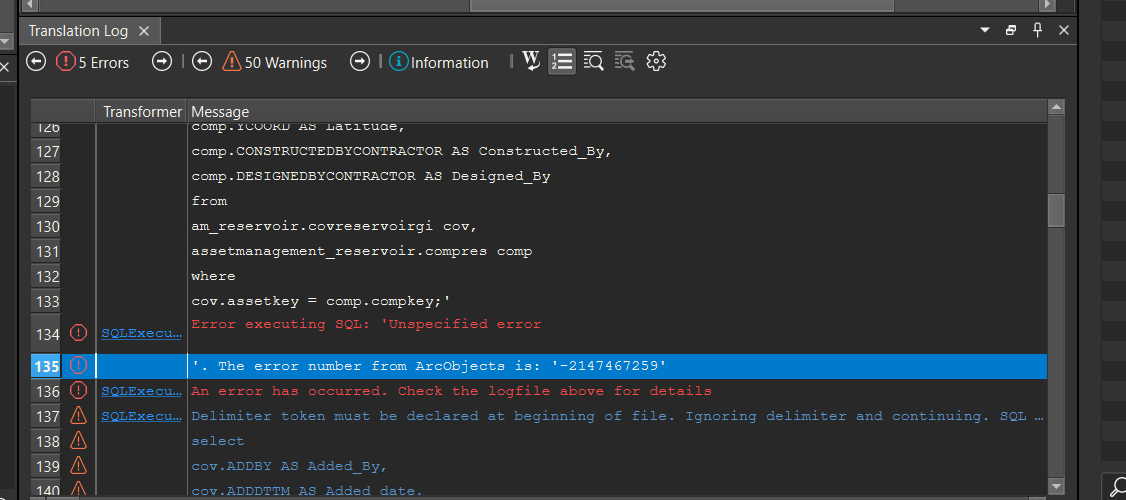
Would I be going the right route here in using the SQL Executor before the ChangeDetector to get the data schema/fields to match prior to plugging them into the ChangeDetector?
Or should I use the PythonCaller to achieve this?
Would that be the correct idea? What about in cases where a user deletes a record in the GIS FC - would that be a separate python caller to handle the deletion cases?
Thanks so much.

