I have a simple yet complex problem that I need to solve with SQL (SQLite) for my FME-script to run efficiantly. This may not be the correct forum, but since there are so many talented people here who enjoy helping out and solving complex problem I thought I'd give it a try here anyway. I have data I want to aggregate but in subgroups - taking z-level into account. It's a geological profile where I want to simplify the incoming data before I create my profile.
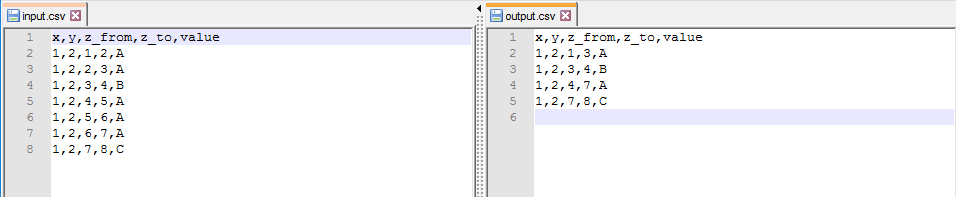
Example data
x, y, z_from, z_to, value
1,2,1,2,A
1,2,2,3,A
1,2,3,4,B
1,2,4,5,A
1,2,5,6,A
1,2,6,7,A
1,2,7,8,C
with SQL I want to aggregate on value but only rows that are adjacent (sort of a dissolve but on non-spatial data). And I want to calculate (also in sql) the correct z_from- and z_to-values. So the result from the example data above should be:
x, y, z_from, z_to, value1,2,1,3,A
1,2,3,4,B1,2,4,7,A1,2,7,8,C
Any help on this will be remembered for all eternity.
Peter
Best answer by jeroenstiers
Hi peteralstorp,
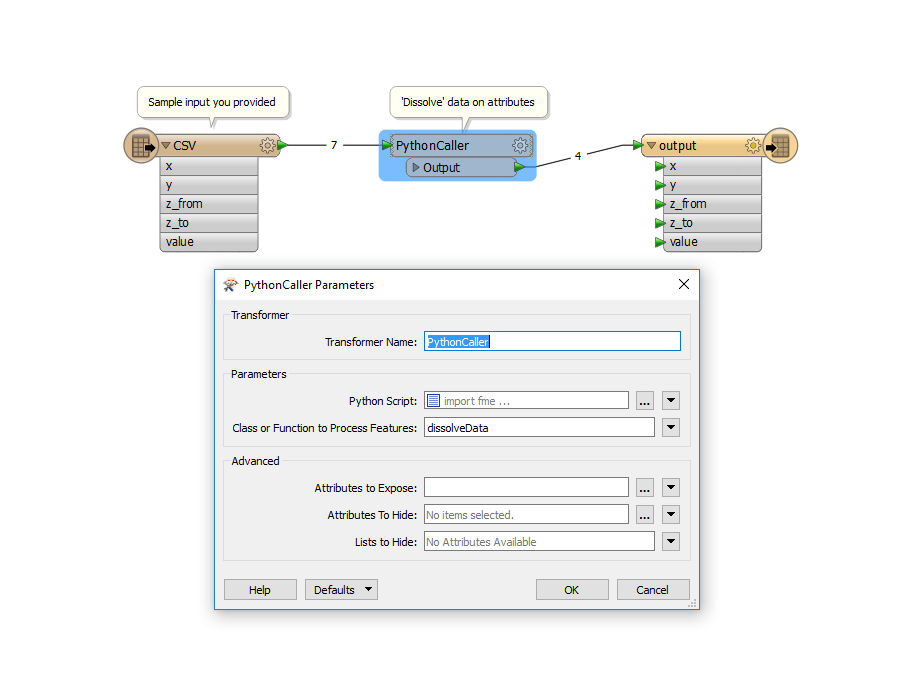
I don't know how to solve this using only SQL but I would like to share a solution using Python because I think it is an easy solution.
The idea is that you store the first feature with a different value than the last one. The moment there is a feature with a different value than the one stored, you update the z_to-value in this stored feature with the last imported feature and export this changed feature to the workspace.
Just let me know if anything is unclear.
Good luck!
import fme import fmeobjects
# Template Class Interface: class dissolveData(object):
# Check if this feature has a value that is different than the last value if feature.getAttribute('value') != self.cValue or self.cValue == -1: # If that is the case, the feature in self.feature should get the z_to value # of the last feature and be exported towards the workspace. if self.feature != -1: self.outputFeature()
# Store this feature as the base of the next output self.feature = feature self.cValue = feature.getAttribute('value')
# Update the z_to-variable self.z_to = feature.getAttribute('z_to')
def close(self): # Making sure we also export the last 'dissolved' feature. self.outputFeature()
def outputFeature(self): # Update the z_to attribute from in the stored feature and export it self.feature.setAttribute("z_to", self.z_to) self.pyoutput(self.feature)
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
Seems to be hard to do that with SQL statement only. I think that using regular transformers is easier.
Do you have to accomplish it with SQL anyway?
Hi T. And thanks for your concern. I would really like to solve it with SQL since this will be a recurring problem that needs fixing. At least I want to avoid a bunch of transformers that are difficult to understand. Is there an easy way to solve this via a regular transformer that you know of please let me know, and I will try it out.
Seems to be hard to do that with SQL statement only. I think that using regular transformers is easier.
Do you have to accomplish it with SQL anyway?
Assume that the features are sorted by "value" and "z_from" ascending. If the features aren't sorted, sort them with the Sorter beforehand.
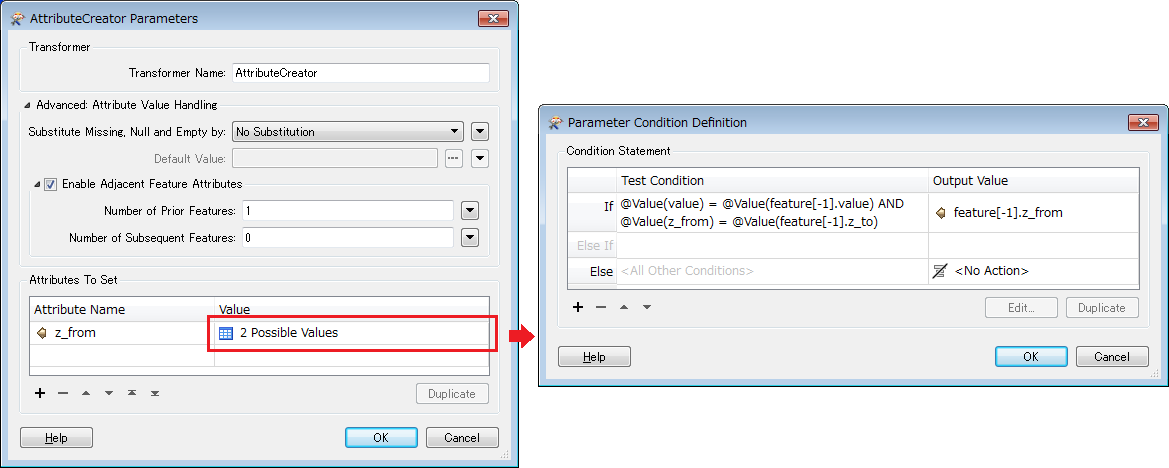
1. AttributeCreator: if {the current feature and the previous feature have the same "value"} and {"z_from" of the current record is equal to the "z_to" of the previous record}, replace "z_from" of the current feature with "z_from" of the previous feature.
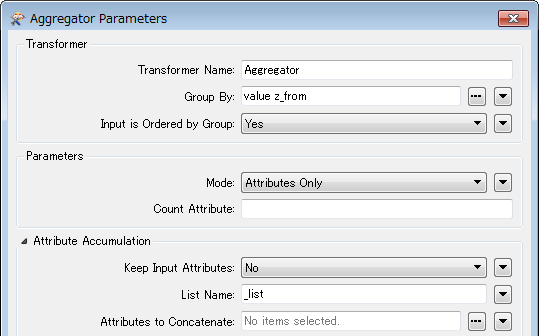
2. Aggregator: aggregate the features grouping by "value" and "z_from", and save all attributes into a list.
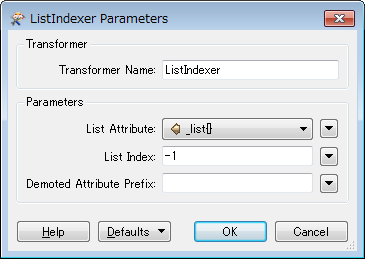
3. ListIndexer: extract tha last element of the list.
Seems to be hard to do that with SQL statement only. I think that using regular transformers is easier.
Do you have to accomplish it with SQL anyway?
Thank you so much, this feels like you set me off on the correct path! I didn't know how to use the Enable Adjacent Feature-function. However, now I still get the same amount of rows as I start up with so something must be wrong, I can't figure it out. Do you have any ideas what might cause this?
I think you had the group by in the Aggregator wrong. You wanted to Group on X, Y and Value like in the LineJoiner and not on Z_from.
Hi @erik_jan, since the values of x and y of all features are identical in the data example, I thought they can be omitted in the Aggregator setting. If x and y should be considered as group identifiers, of course they should be set to the "Group By", as you mentioned.
The AttributeCreator modifies "z_from" so that it contains an identical value (i.e. first "z_from" in a group) for each group. It's the key point of the first solution.
Hi @erik_jan, since the values of x and y of all features are identical in the data example, I thought they can be omitted in the Aggregator setting. If x and y should be considered as group identifiers, of course they should be set to the "Group By", as you mentioned.
The AttributeCreator modifies "z_from" so that it contains an identical value (i.e. first "z_from" in a group) for each group. It's the key point of the first solution.
I don't know how to solve this using only SQL but I would like to share a solution using Python because I think it is an easy solution.
The idea is that you store the first feature with a different value than the last one. The moment there is a feature with a different value than the one stored, you update the z_to-value in this stored feature with the last imported feature and export this changed feature to the workspace.
Just let me know if anything is unclear.
Good luck!
import fme import fmeobjects
# Template Class Interface: class dissolveData(object):
# Check if this feature has a value that is different than the last value if feature.getAttribute('value') != self.cValue or self.cValue == -1: # If that is the case, the feature in self.feature should get the z_to value # of the last feature and be exported towards the workspace. if self.feature != -1: self.outputFeature()
# Store this feature as the base of the next output self.feature = feature self.cValue = feature.getAttribute('value')
# Update the z_to-variable self.z_to = feature.getAttribute('z_to')
def close(self): # Making sure we also export the last 'dissolved' feature. self.outputFeature()
def outputFeature(self): # Update the z_to attribute from in the stored feature and export it self.feature.setAttribute("z_to", self.z_to) self.pyoutput(self.feature)
I'm unclear what is wrong in the actual situation. Please explain the situation in more detailed.
Another thought. This may also be resolved with geometric operations, I think it's an advantage of FME.
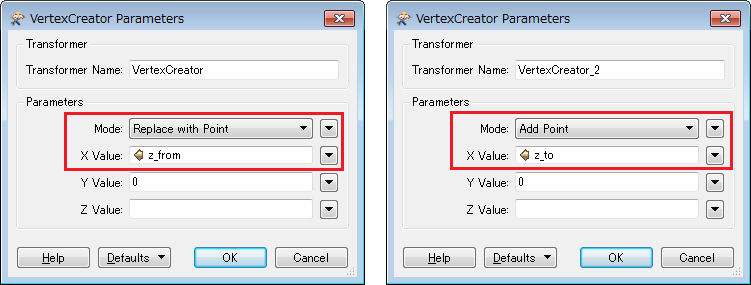
1. Two VertexCreators: translate each feature to a line segment (z_from, 0) - (z_to, 0).
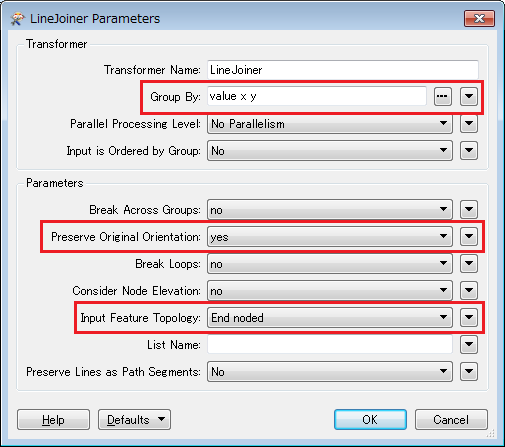
2. LineJoiner: connect the line segments grouping by attributes except z_*.
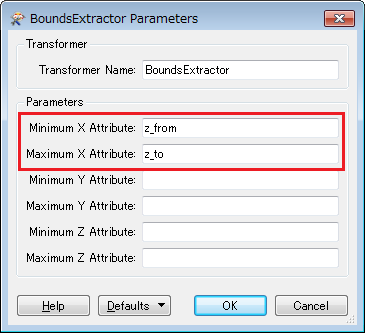
3. BoundsExtractor: extract {minimum x, maximum x} of the resulting line as {z_from, z_to}.
Addition. If z_from and z_to aren't increasing in the connecting order, consider using two CoordinateExtractors instead of the BoundsExtractor.
@takashi I think the problem is that the prior feature (when read) already has been altered with a new z_from-value. Could that be the problem? The transformer documentation says "When retrieving the value of a prior feature, any changes made by the AttributeCreator to that feature will take effect."
Seems to be hard to do that with SQL statement only. I think that using regular transformers is easier.
Do you have to accomplish it with SQL anyway?
@takashi I think the problem is that the prior feature (when read) already has been altered with a new z_from-value. Could that be the problem? The transformer documentation says "When retrieving the value of a prior feature, any changes made by the AttributeCreator to that feature will take effect."
Seems to be hard to do that with SQL statement only. I think that using regular transformers is easier.
Do you have to accomplish it with SQL anyway?
I would like to mark this as a correct answer as well, but since the Attributecreator-problem (looking at features that have already been altered) doesn't seem to work I await your answer/comments first. Anyway, big thanks again, your efforts are noticed and most welcome!
I don't know how to solve this using only SQL but I would like to share a solution using Python because I think it is an easy solution.
The idea is that you store the first feature with a different value than the last one. The moment there is a feature with a different value than the one stored, you update the z_to-value in this stored feature with the last imported feature and export this changed feature to the workspace.
Just let me know if anything is unclear.
Good luck!
import fme import fmeobjects
# Template Class Interface: class dissolveData(object):
# Check if this feature has a value that is different than the last value if feature.getAttribute('value') != self.cValue or self.cValue == -1: # If that is the case, the feature in self.feature should get the z_to value # of the last feature and be exported towards the workspace. if self.feature != -1: self.outputFeature()
# Store this feature as the base of the next output self.feature = feature self.cValue = feature.getAttribute('value')
# Update the z_to-variable self.z_to = feature.getAttribute('z_to')
def close(self): # Making sure we also export the last 'dissolved' feature. self.outputFeature()
def outputFeature(self): # Update the z_to attribute from in the stored feature and export it self.feature.setAttribute("z_to", self.z_to) self.pyoutput(self.feature)
jeroenstiers My only problem now is that I need to aggregate on an id (called miid) also, since I have many groups of profiles going through the same script. Do you have a suggestion on how to do this? So, the comparison on 'value' should also incorporate a control that miid is the same... Am I being unclear?
I'm unclear what is wrong in the actual situation. Please explain the situation in more detailed.
Another thought. This may also be resolved with geometric operations, I think it's an advantage of FME.
1. Two VertexCreators: translate each feature to a line segment (z_from, 0) - (z_to, 0).
2. LineJoiner: connect the line segments grouping by attributes except z_*.
3. BoundsExtractor: extract {minimum x, maximum x} of the resulting line as {z_from, z_to}.
Addition. If z_from and z_to aren't increasing in the connecting order, consider using two CoordinateExtractors instead of the BoundsExtractor.
For the record. I just tried this solution and it works fine! Thank you, Takashi. From what I can gather it's not possible to mark two solutions as the correct answer.
jeroenstiers My only problem now is that I need to aggregate on an id (called miid) also, since I have many groups of profiles going through the same script. Do you have a suggestion on how to do this? So, the comparison on 'value' should also incorporate a control that miid is the same... Am I being unclear?
Hi peteralstorp,
I think I understand what you need. Instead of having 1 attribute to aggregate on, you have two. Is this correct?
If so, the easiest solution is to create a new attribute concatenating both. Doing so will result in the requested behaviour. If you would like to solve this without concatenating, you just have to add three lines of code to (1) store also the second attribute (line 11), (2) check if this second attribute has changed (line 15) and (3) update the stored value (line 24).
I think I understand what you need. Instead of having 1 attribute to aggregate on, you have two. Is this correct?
If so, the easiest solution is to create a new attribute concatenating both. Doing so will result in the requested behaviour. If you would like to solve this without concatenating, you just have to add three lines of code to (1) store also the second attribute (line 11), (2) check if this second attribute has changed (line 15) and (3) update the stored value (line 24).
Does this answer your question?
.@peteralstorp
Of course. As simple as that. Thanks again @jeroenstiers! I am so grateful for FME Knowledge and all its members.