Hello Folks,
I have been presented with an interesting issue.
I have a CSV which consist of data with multiple headers and related data for those headers.
#header 1 and values
observationId,broid,_response_body_new,_http_status_code
id_01682157639,GLD000000036023,"""BRO-ID"",""bronhouder"",,""kwaliteitsregime"",""datum eerste meting"",""datum recentste meting""
GLD000000036023"",""50200097"",,""IMBRO"",""(2005-11-27, JJJJ-MM-DD)"",""(2025-04-10, JJJJ-MM-DD)""
,,,,,
#header 2 and values
""put BRO-ID"",""put buisnummer"",,""monitoringnet BRO-ID"",,
GMW000000074173"",""2"",,,,
,,,,,
#header 3 and values
observatie ID"",""start observatieperiode"",""eind observatieperiode"",""observatietype"",""mate beoordeling"",""observatieproces ID""
id_OMO_95135"",""(2024-07-18, JJJJ-MM-DD)"",""(2025-04-10, JJJJ-MM-DD)"",""reguliereMeting"",""volledigBeoordeeld"",""id_OP_95135""
,,,,,
#header 4 and values
""tijdstip meting"",""waterstand"",""status kwaliteitscontrole"",""censuurreden"",""censuurlimietwaarde"",""interpolatietype""
2024-07-18T12:00:00+02:00"",""30.602"",""goedgekeurd"",,,""discontinu""
…
,,,,,
,,,,,
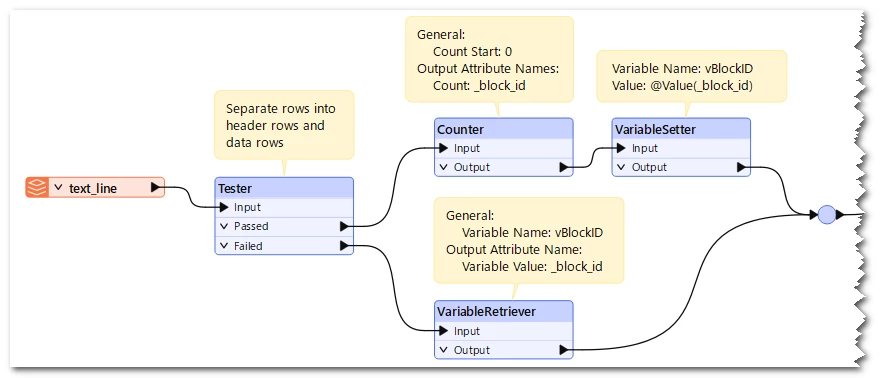
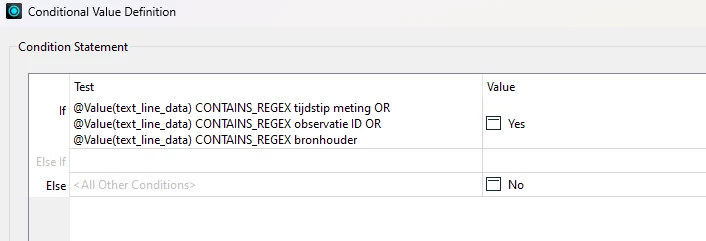
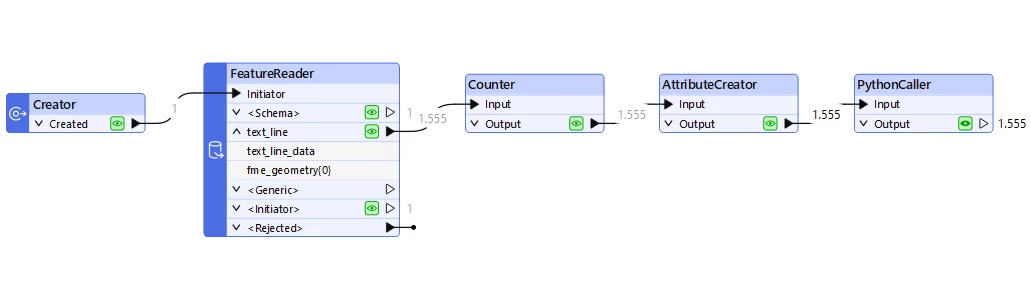
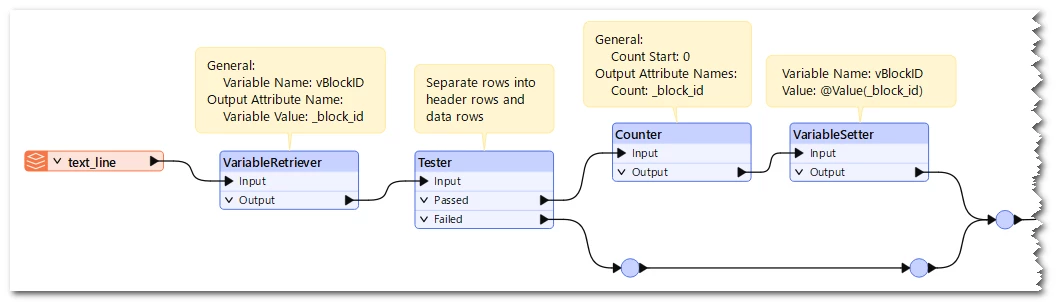
and then header 3 & 4 (are related to each other as well) repeat throughout the file.
How can I extract all these headers and their values into chunks in FME.
a single CSV with one header is no issue for me to get data out of. maybe i am missing something so obvious?
Please guide me
Linked a sample CSV for better understanding.