Hello,
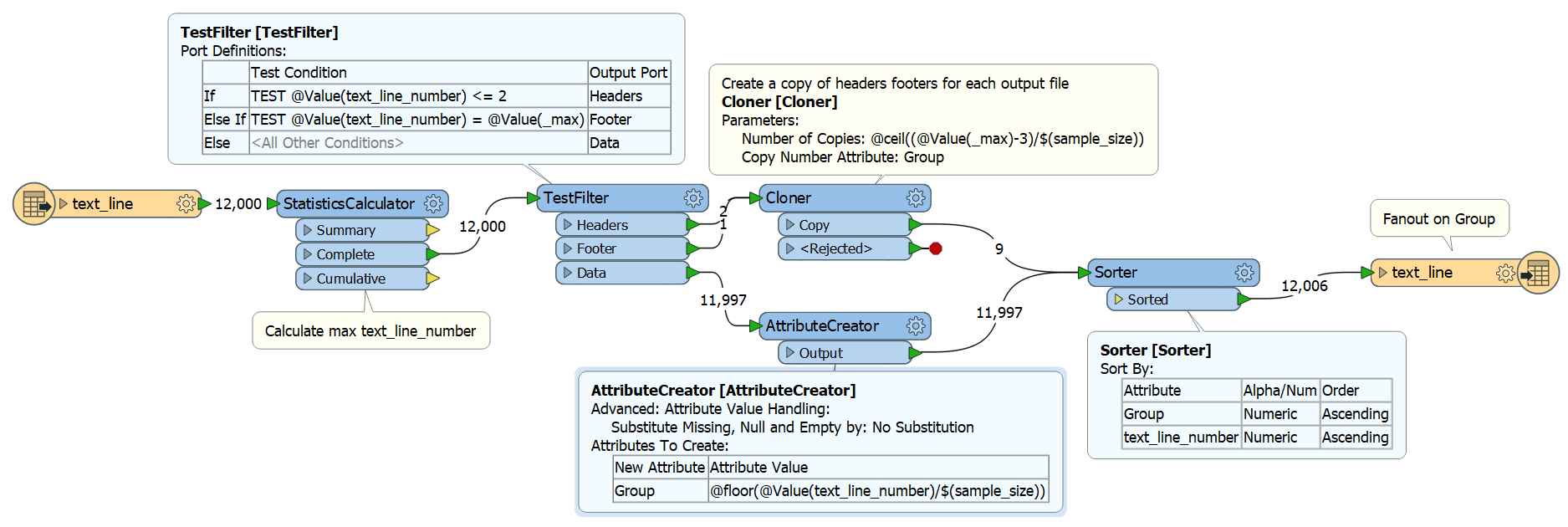
I have a CSV file with 70,000 records. It has a header row identified by 10 in the first column. The data rows have 20 in the first column and the footer row has a 99 in the first column. I can split out the three row types, do stuff to the data rows and then combined them all back together again in the correct order – 10, 20, 99.
However, the output file is too big for our thirdparty import routine to handle so I need a way of chunking the data into files with, say, 5,000 records in each. Each file needs the original header row (4 columns), the 5000 data rows (15 columns) and an updated footer row (2 columns) with a 99 and a count of the number of data rows in it. The importer should be able to loop through these smaller files without taxing the underlying JVM.
I have got it mostly working using a fanout on the dataset using @Count(fanout,1,10) which creates 10 folders with a CSV file in each. However the header row gets written to the first file and footer row only gets written to the last file. The other files don’t have the header or footer row. I’ve also tried putting in a ModuloCounter and fanning out on the module_count attribute. Again, the first file gets the header row and another file gets the footer row when each file needs a header and footer row.
Any suggestions from the FME Hive Mind?
Thanks in advance.