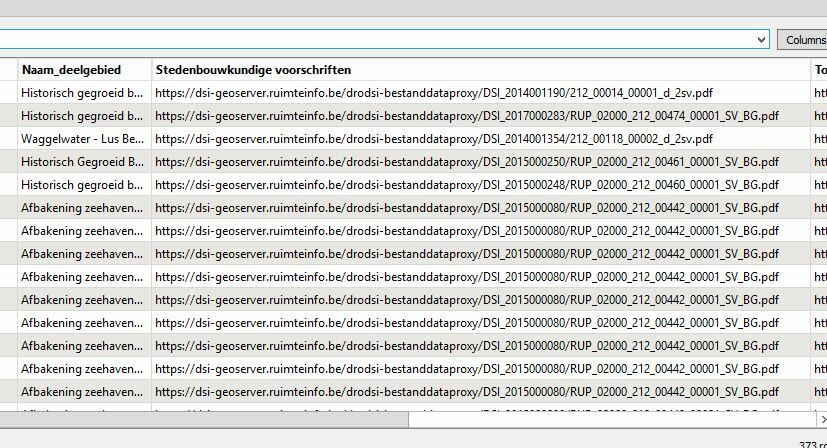
For some reason it won't work if I plug in the url in a FeatureReader, but if I use a HTTPCaller to save a local copy of the PDF and then open that using the FeatureReader it does work.
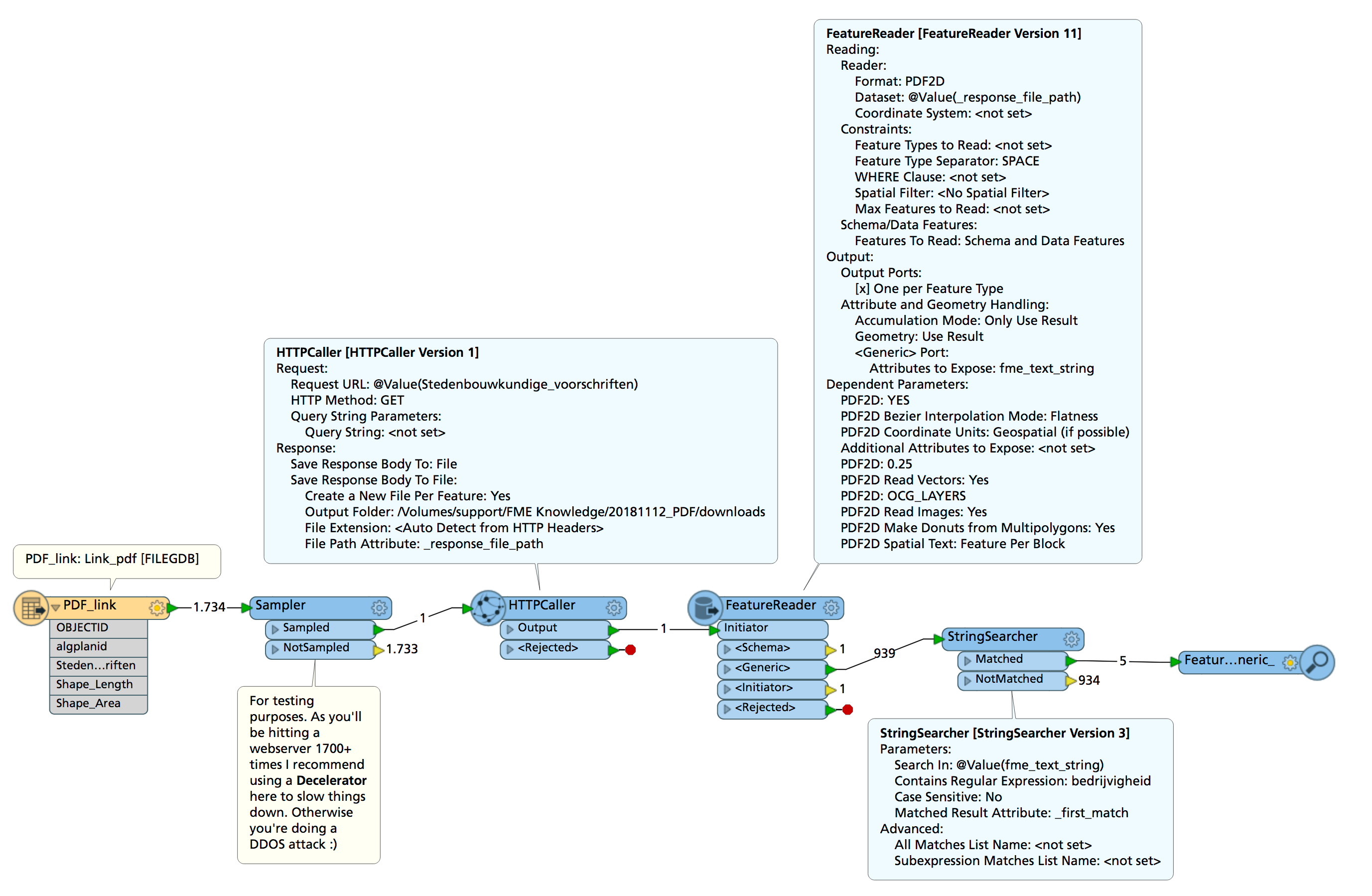
pdf_searching.fmw
Note that I strongly recommend a Decelerator. You will be hitting the webserver that hosts the PDF once per feature, so that's over 1700 times for this dataset. If you do that at FME's regular speed it might overload it or be seen as a DDOS attack (I've once done that).
You're also very much dependent on how the PDF is structured. The first one that I've used as a sample appears to be a fairly good one, but there's no guarantee they'll all be like that. If it's a scanned form you're out of luck.
A very important parameter is in the FeatureReader, make sure that in the PDF parameters there you set the Spatial Text one to "Feature Per Block". That way it tries to make one text object per line.