Hello,
I periodically load the latest version of topographic data (shape format) from many municipalities in our GIS system. The data is loaded per topographic object (for example: a workbench for buildings, an other workbench for roads, ...). Each workbench loads the data for all municipalities together.
The first time the data was loaded the source contained 94 shape files (94 municipalities). The second time this was 92 (9 old deleted and 7 new added).
I have adjusted the change in the data manually (update features and connect the new ones), a work that does take some time. Should the number of municipalities change again next time, the reader must be updated again.
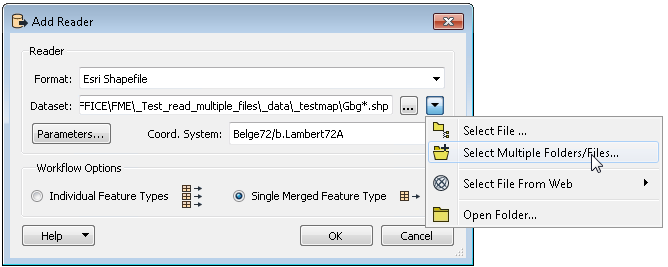
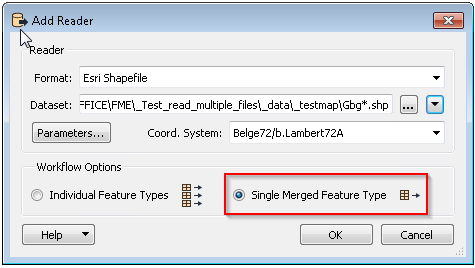
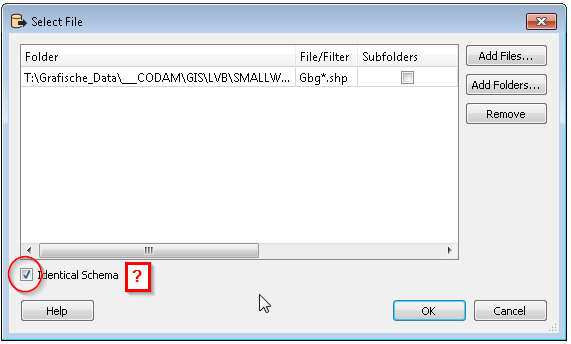
Is there a possibility to automatically read all shape files (which can change in number and file name) in one and the same folder, without the need to make manual adjustments?
Thanks!
Luc