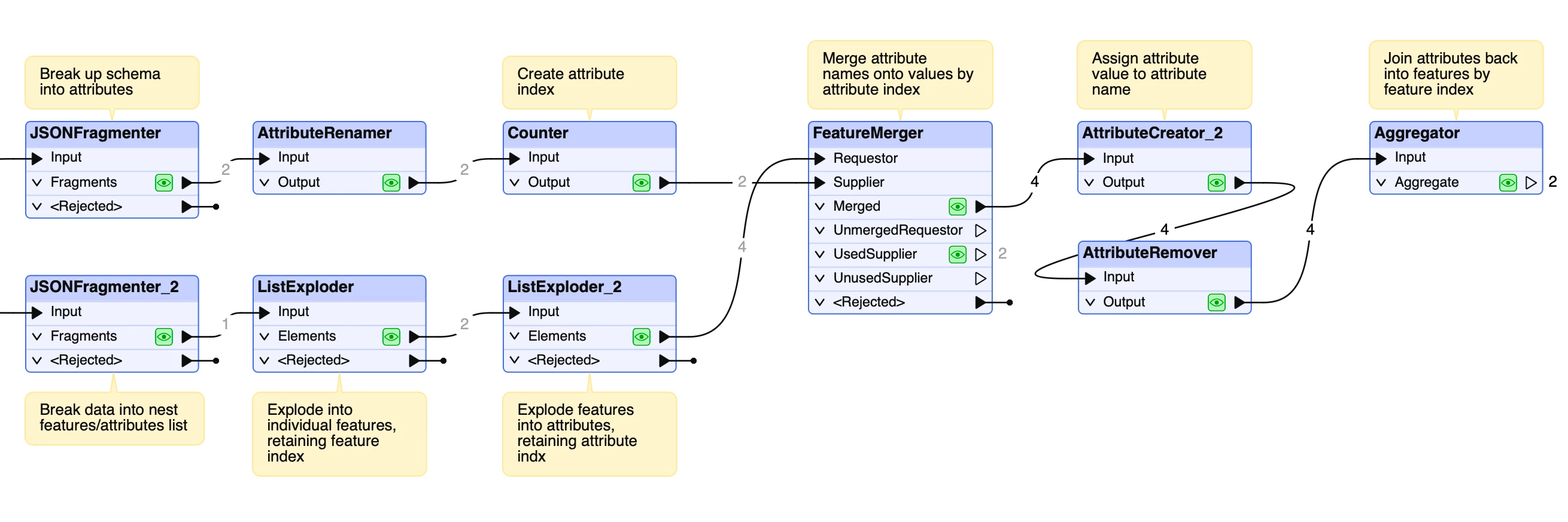
Does anyone know a good built-in or pre-created solution to read “Tabular JSON” that’s in a format of schema followed by values rather than key:value? See example below. I have ~40 schema values but only included 2. I’m looking for something dynamic rather than manually assigning column names in a specific order.
{
"schema": {
"title": "Data Export",
"type": "array",
"properties": {
"id": {
"title": "id",
"type": "integer",
"default": "",
"minimum": -2147483648.0,
"maximum": 2147483647.0
},
"code": {
"title": "code",
"type": "string",
"default": ""
}
}
},
"data": [
[
1,
"DEMO1234"
]
]
}
")