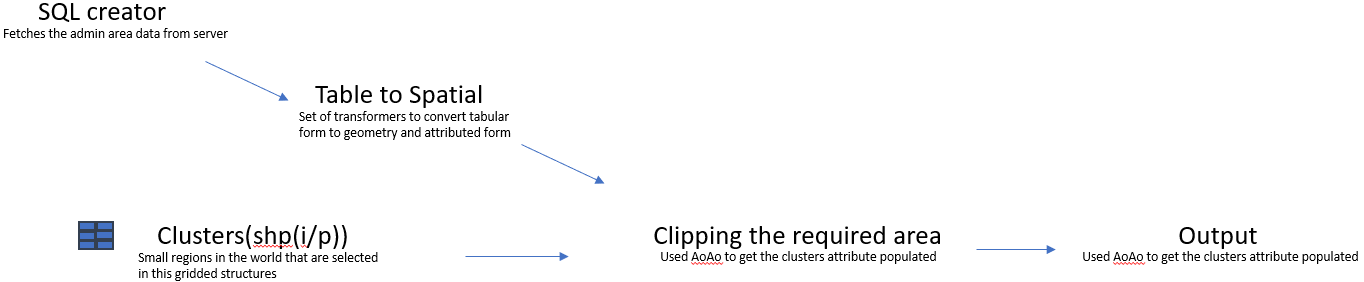
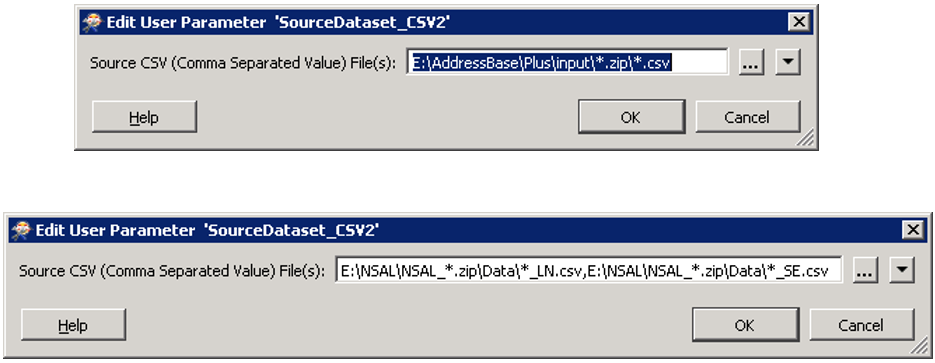
Hello.
Can we control the flow of the in[ut gdb feature classes so that the first feature class is read first, goes to the complete workspace and the output is written? Then the second feature class is read, goes to the complete workspace and the output is written and so on! Thanks.