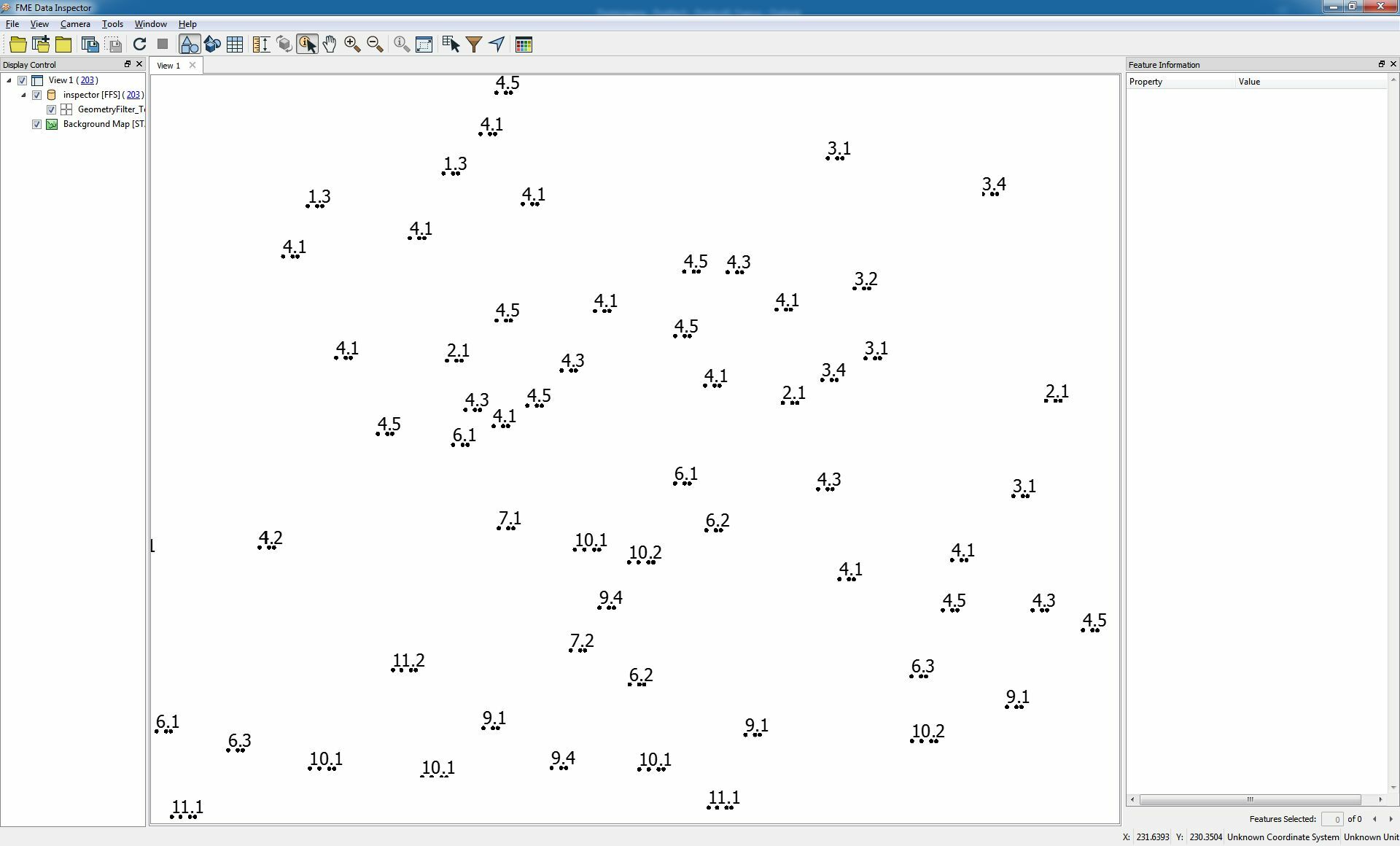
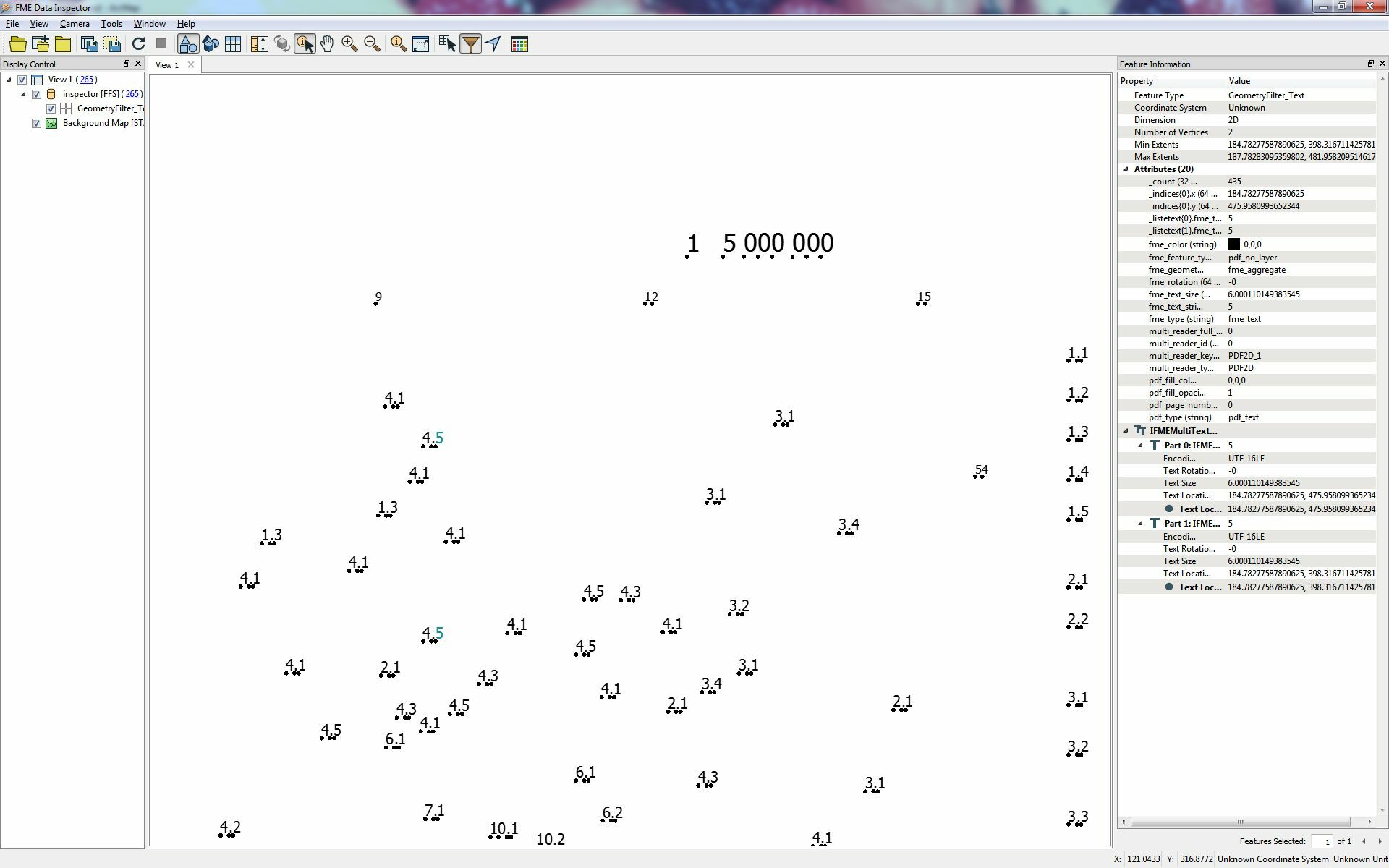
I've extracted text from a pdf file
but i have to group or aggregate this text now...as you see on my screenshot i have such text as "4.1" or "5.2" etc...but they are all one point with text attribute as a result from PDF Reader...
How can i aggregate them to one feature with one attribute which contains "4.1" e.g ?
I know its simple but i tried Neighborhoodfinder Neighboraggregator and so on....result isnt right..
So for you specialists no prob i think..
Greetz and Cheers
Franco