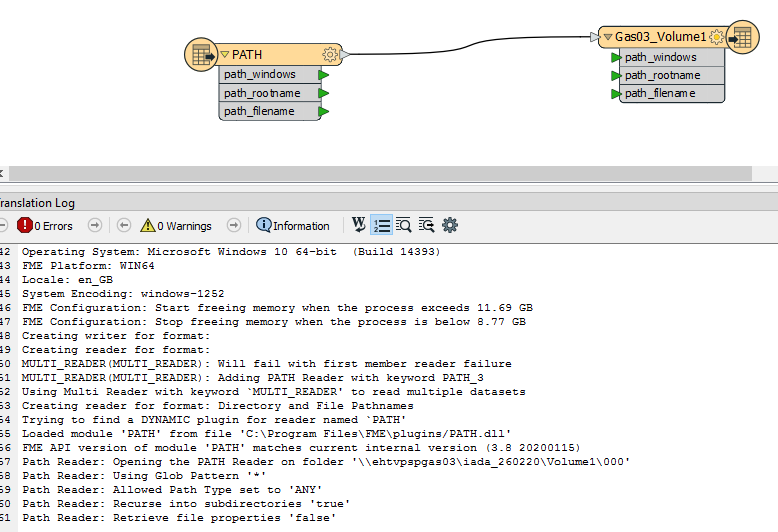
When running a simple Pathreader on files on a network share it runs fine . But when I choose the recursive parameter the translation just gets to "retrieve file properties 'false' " and no further progress is made
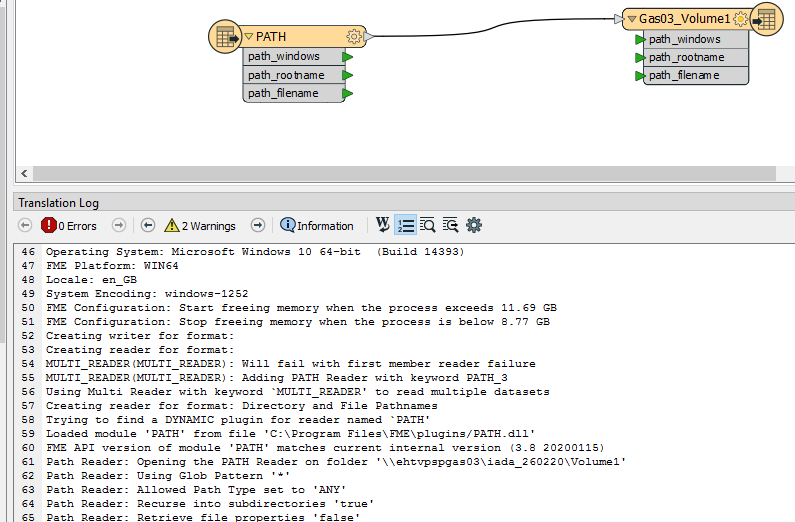
The 2 warnings are :
Feature Caching is ON
The workspace may run slower because features are being recorded on all output ports.
any ideas why this should happen?