My goal is to read log files from Amazon 33 and parse them into a database
The log files look like this:-
#Version: 1.0
#Fields: date time x-edge-location sc-bytes c-ip cs-method cs(Host) cs-uri-stem sc-status cs(Referer) cs(User-Agent) cs-uri-query cs(Cookie) x-edge-result-type x-edge-request-id x-host-header cs-protocol cs-bytes time-taken x-forwarded-for ssl-protocol ssl-cipher x-edge-response-result-type cs-protocol-version fle-status fle-encrypted-fields c-port time-to-first-byte x-edge-detailed-result-type sc-content-type sc-content-len sc-range-start sc-range-end
2020-07-03 13:39:54 LHR62-C3 1571 148.00.00.00 GET d36on651kzt577.cloudfront.net / 200 https://URL/2020/07/02/fooo/ Mozilla/5.0%20(Windows%20NT%2010.0;%20Win64;%20x64)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/83.0.4103.116%20Safari/537.36 - - Hit gIanUGtmvquSunAiRJFbhFdPbexwpIV2DbtYUJ7XtVOKZopkUl1uEw== foo.com https 427 0.001 - TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 Hit HTTP/2.0 - - 58606 0.001 Hit text/html;%20charset=utf-8 1234 - -
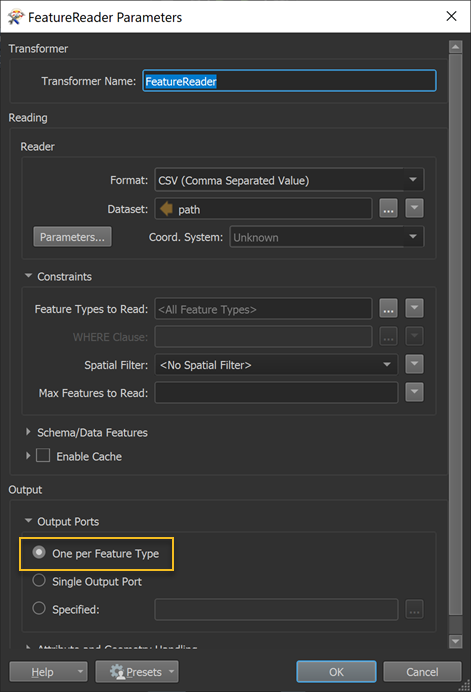
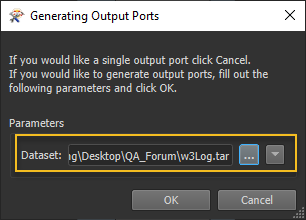
I am downloading the files locally and then reading them using a FeatureReader with CSV format. I have set the Dataset parameters to be tab delimited with no field names line and to read data from line 3 onward.
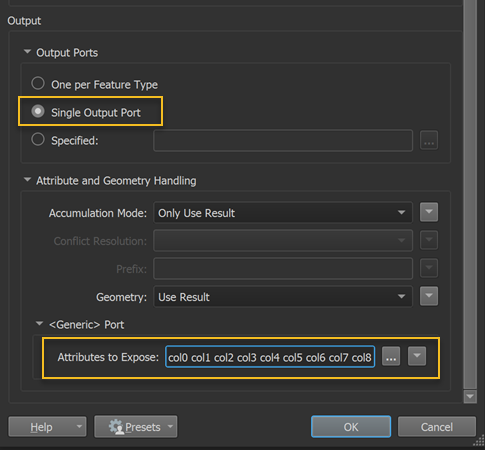
Is it possible for me to set the field headings manually? I can see the data at the "Generic" output port and if I inspect this and show all columns I can see col0 - col32 has been read in correctly. But I cannot figure out how to expose these columns so I can rename them and load them into the database?
To add a bit more information here is my flow
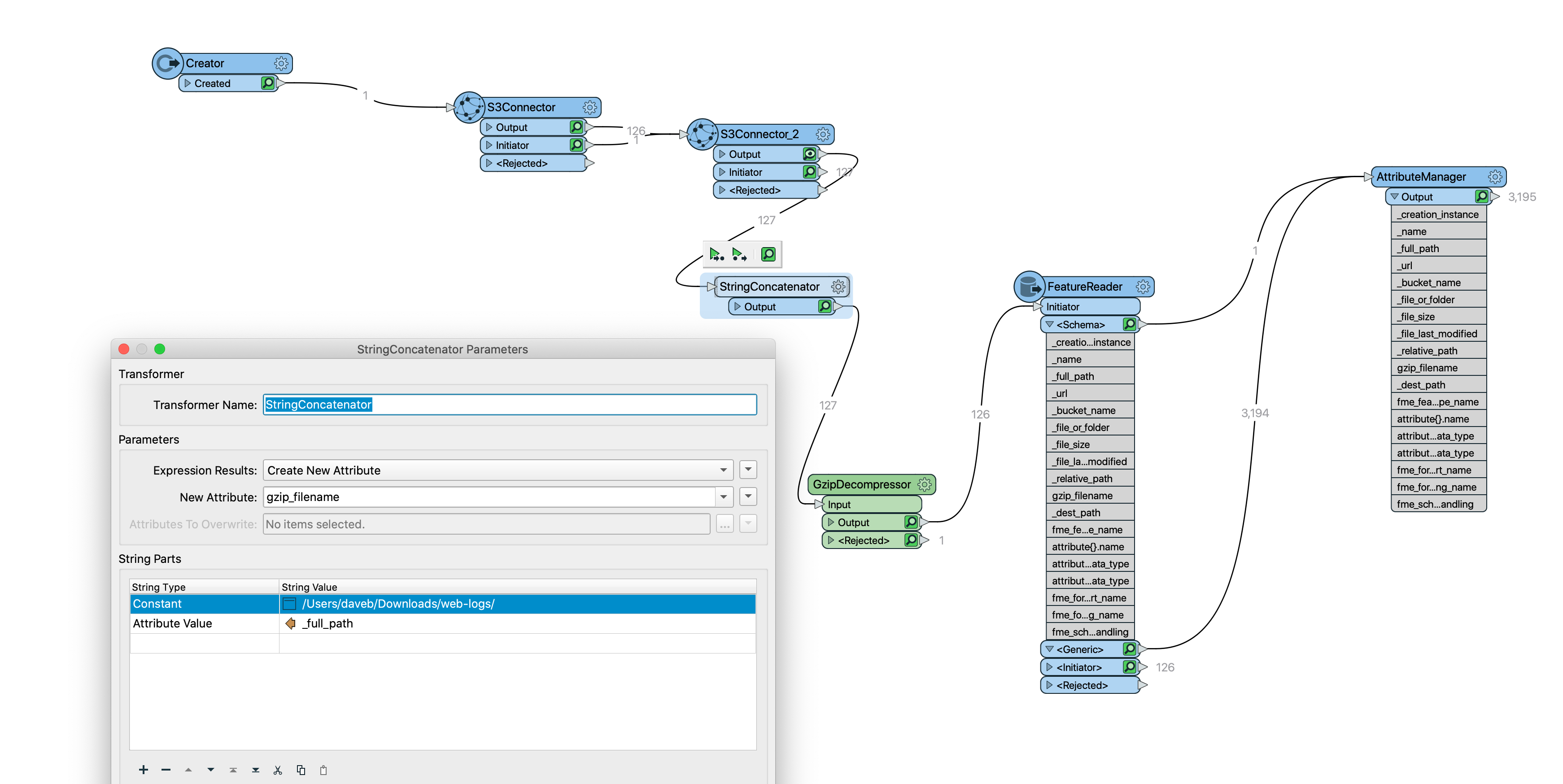
The files downloaded from S3 are in GZIP format
I could not find a way of getting the FULL path to the downloaded file to pass to the gzip decompressor so had to append the root path to the file name. As a result this appears to stop the FeatureReader from exposing the columns read. I need a way of telling it these manually.
I have confirmed that the dynamic file name is the problem
If I select a single GZ file for the Feature Reader then the columns are available.