")

In a SDE reader, you have the option to ‘Resolve Domains’:
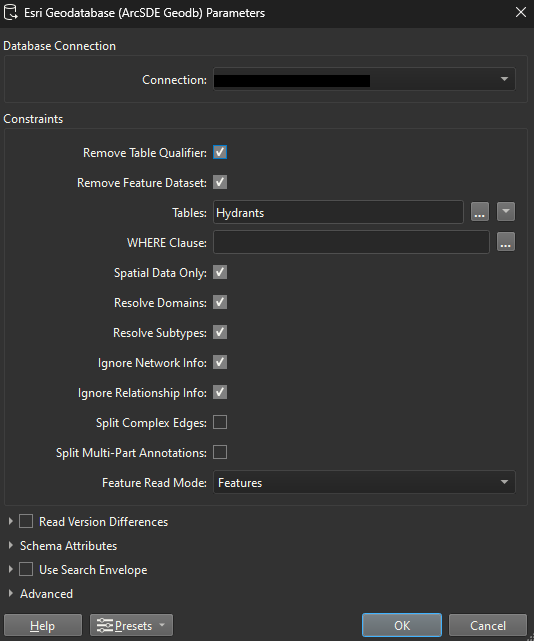
In this example, this will take fields that have a domain, and create a new field with a suffix ‘_resolved’ and populates it with the descriptions from the coded values.
I.e:

The original field with the domain codes is ‘Accuracy_Spatial_Source’, while the ‘Accuracy_Spatial_Source_resolved’ are the domain descriptions.
Once the codes are resolved, I no longer need the original fields, is there a simply way to remove these automatically?
Sure, I can use an AttributeManager and remove them manually, however, it is not very practical or efficient when having more than 50 fields.
One way to somewhat ‘cheat’ is to use a BulkAttributeRenamer and remove the suffix ‘_resolved’ to basically ‘overwrite’ the original fields, however, this causes schema issues.
Another method I tested was using a PythonCaller and generating a list of all the “unresolved” fields, however, I could not find a way after to bulk remove the attributes from a list.
Has anyone figured out a way to do this?