Hi, I have the following csv sheet created with FME
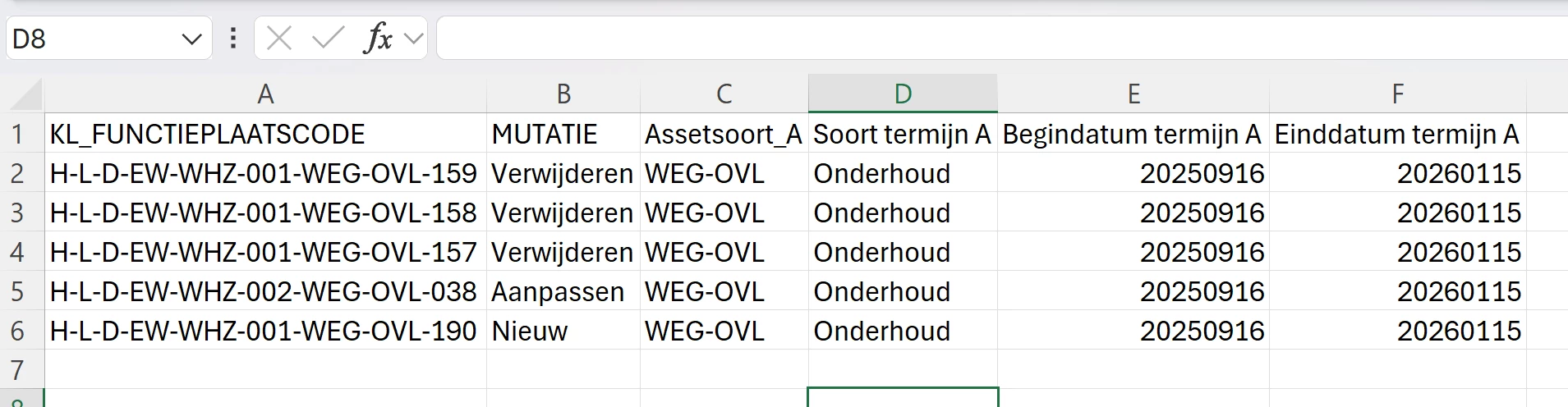
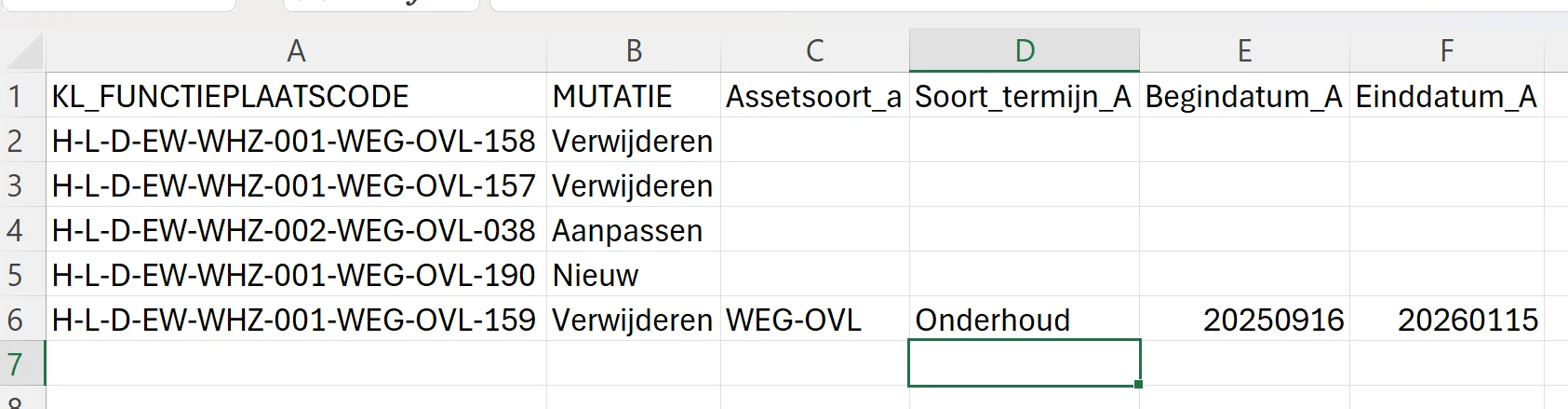
That is not exactly what I want. I would like to see the following format:
The third column is empty, and for the last 4 columns only 1 row is needed. How can I achieve that? The values in the last 4 columns are purely inserted in the user interface at the start, not more than that.
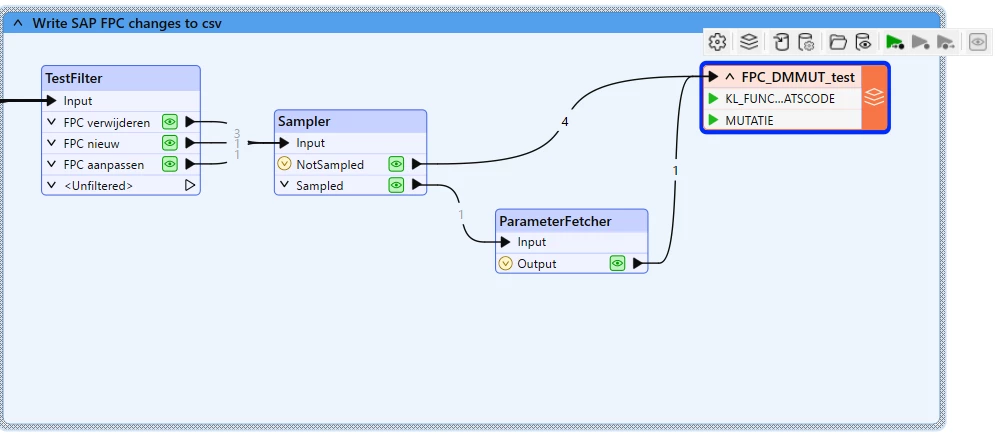
Below is the part of FME:
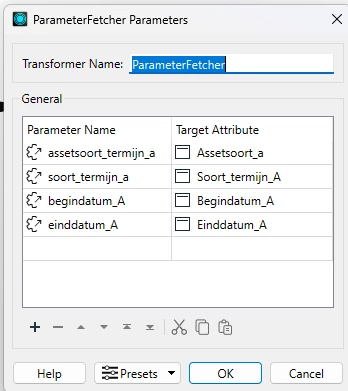
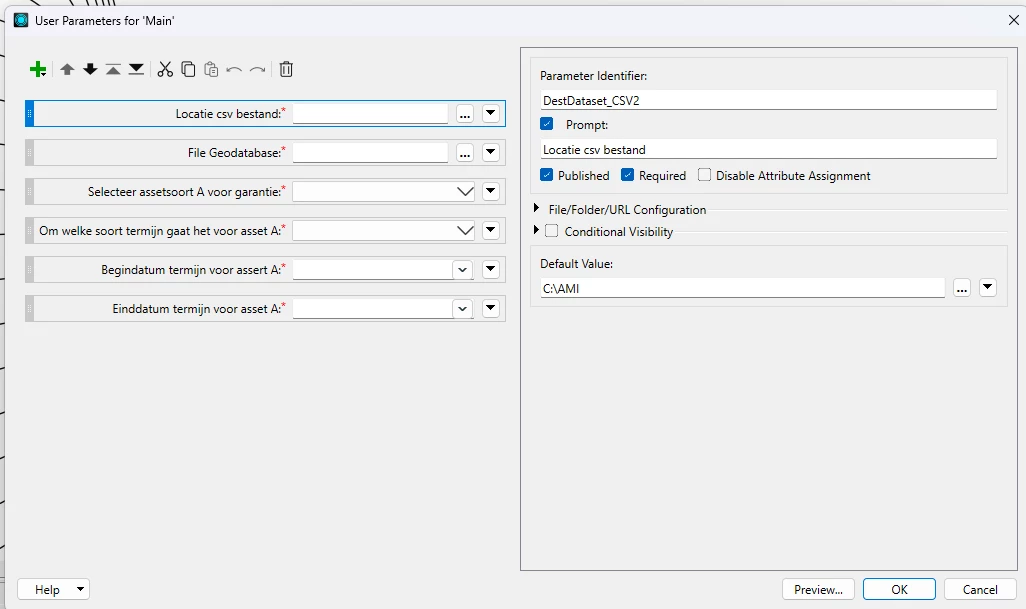
The user parameters of the writer are as follows:
Any tips?
Best answer by takashi
Hi @sparks ,
For the last four columns, you can write the parameter values into only the first row with:
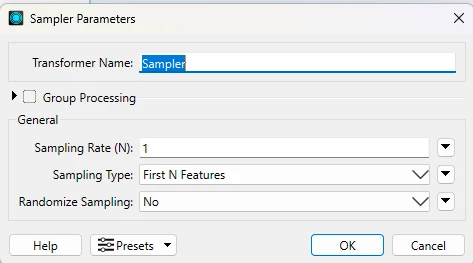
Insert Sampler before the CSV writer feature type to select the first feature (Sampling Rate (N): 1, Sampling Type: First N Features).
Add ParameterFetcher and connect it to the Sampled port of the Sampler to get the four parameter values and assign them to the destination four attributes (Assetsoort_A, Soort termjin A, ...) .
Send all the features from the ParameterFetcher and NotSampled port of the Sampler to the writer feature type.
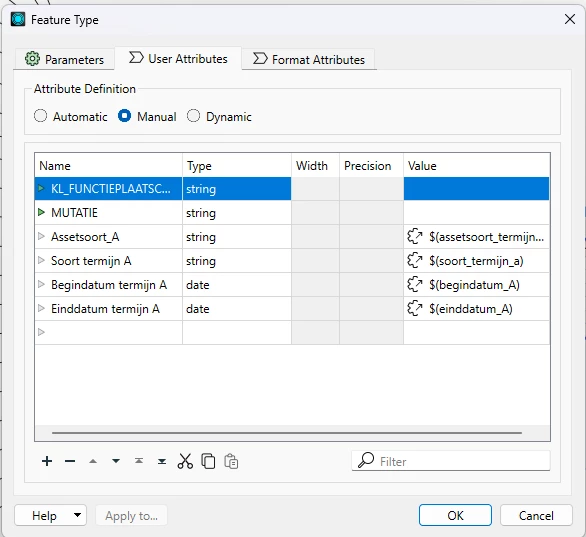
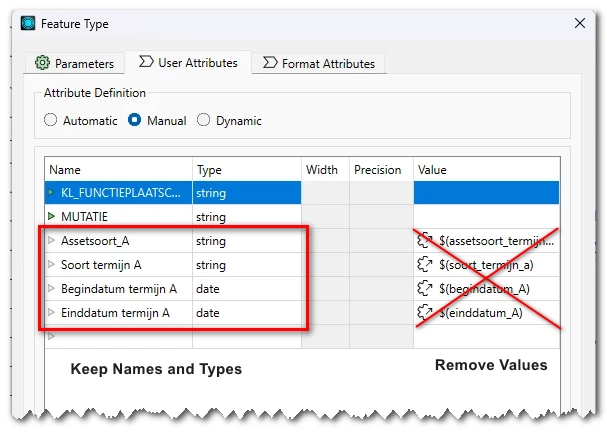
In User Attributes tab, the CSV writer feature type, remove values from the four columns.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
For the last four columns, you can write the parameter values into only the first row with:
Insert Sampler before the CSV writer feature type to select the first feature (Sampling Rate (N): 1, Sampling Type: First N Features).
Add ParameterFetcher and connect it to the Sampled port of the Sampler to get the four parameter values and assign them to the destination four attributes (Assetsoort_A, Soort termjin A, ...) .
Send all the features from the ParameterFetcher and NotSampled port of the Sampler to the writer feature type.
In User Attributes tab, the CSV writer feature type, remove values from the four columns.
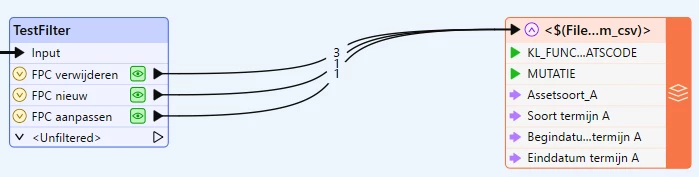
Thanks for the reply, much appreciated. I tried with the following schema:
The result is that not any of the last 4 columns is visible in the output, only the columns KL_FUNCTIEPLAATSCODE and MUTATIE are shown.
Again, the data of the last 4 columns are not available in the input of Testfilter, it is derived from the input at the start of the run, as defined in the user parameters:
In the File Geodatabase among others the values for KL_FUNCTIEPLAATSCODE and MUTATIE can be found. File Geodatabase is the input for the TestFilter. That is why I would like to know how to add the 4 columns in the csv output, based on the input in the User Parameters, and to be shown in one row only.
Careful reading is an art :-) Please accept my apologies.
The output is:
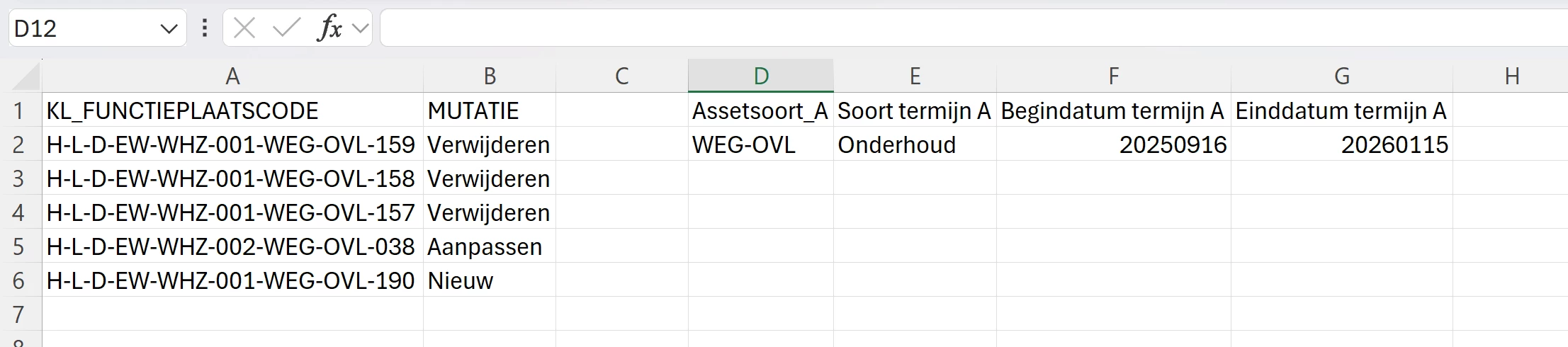
Much better! Thanks! I don't know if it is possible to get the values of the latest 4 column in the second row, below the colum names? In practice the list of “KL_FUNCTIEPLAATSCODE” can be very long, more than 100 values. It would be nice to have the data of the latest 4 columns up in the sheet, to avoid scrolling down to the end of the sheet.
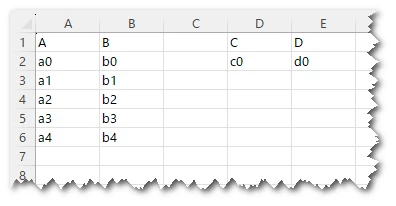
As stated in the original post, I would like to add an empty column between the first two columns and the other columns. How do you do that?
I suspect that Feature (Data) Caching on the Sampler caused the unexpected processing order of its output ports - Sampled and NotSampled. Try re-running the workspace entirely.
Re-running the workspace entirely helps, thanks! I should study how the Sampler works, it is very useful.
Now the final step: adding an empty column between the first two columns and the other columns :-). There must be a simple solution, I think. Sorry for my limited knowledge of FME, but I’m learning :-)
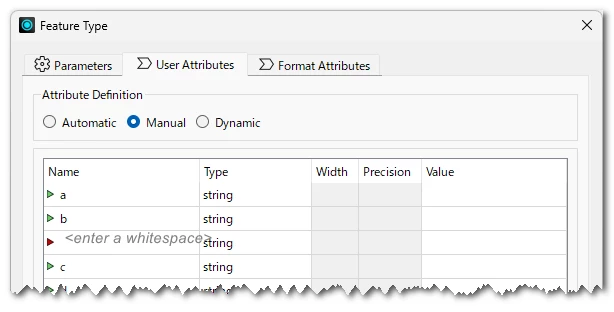
CSV writer doesn't have the ability to write a column with exactly empty (no characters) name, but in my observation, it seems to be possible to create a column whose name is a whitespace character, something like the screenshot below. Don’t forget set Type to the column too.
@sparks , good to hear that you achieved the goal!
For what it's worth, there is another possible way to create such an irregular csv table with Data File writer or Text File writer, instead of CSV writer.
See the attached workspace example which creates this CSV table with Data File writer. By this way, you can create a table containing exactly empty column name(s).