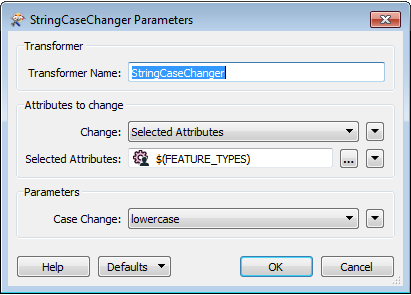
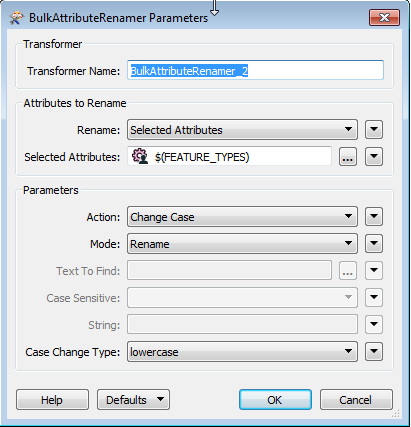
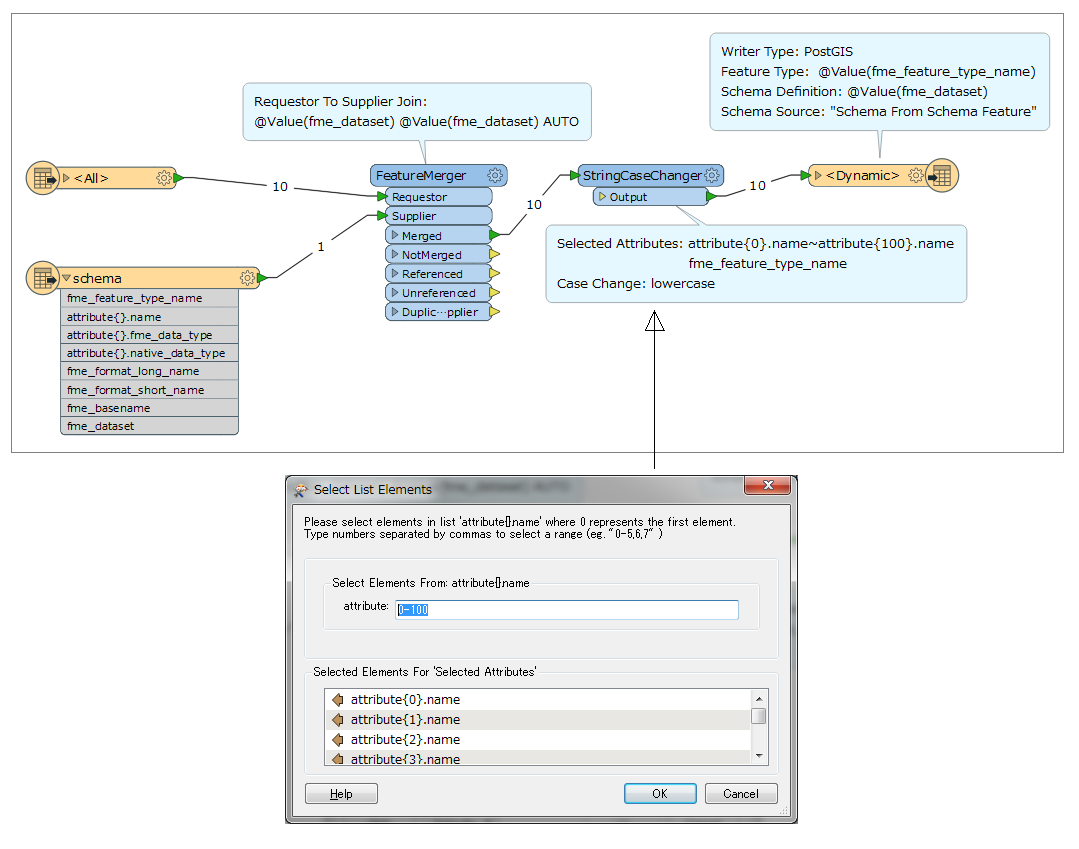
I am using FME 2013 SP2 to bulk load data into PostGIS 9.2 from Oracle 10 using a very simple workbench. I can set the attribute names to lower case in the PostGIS writer (as well as create the GIST index, sequence and primary key) but I also need to set the table names / feature type name to lowercase. I have several hundred tables to copy over and it would be nice to change case automagically rather than manually editing the workbench.
Any suggestions?
Thanks
Ross