I recently posted a question on the r/fme subreddit but am reposting here to see if I have better luck. I’m including the reddit post for context in the Original Post Contents section below.
Since creating the post, I ended up joining the attributes I needed from the JSON to my transformation table but at the cost of decreased performance, see the Update to Original Post section below.
Original Post Contents
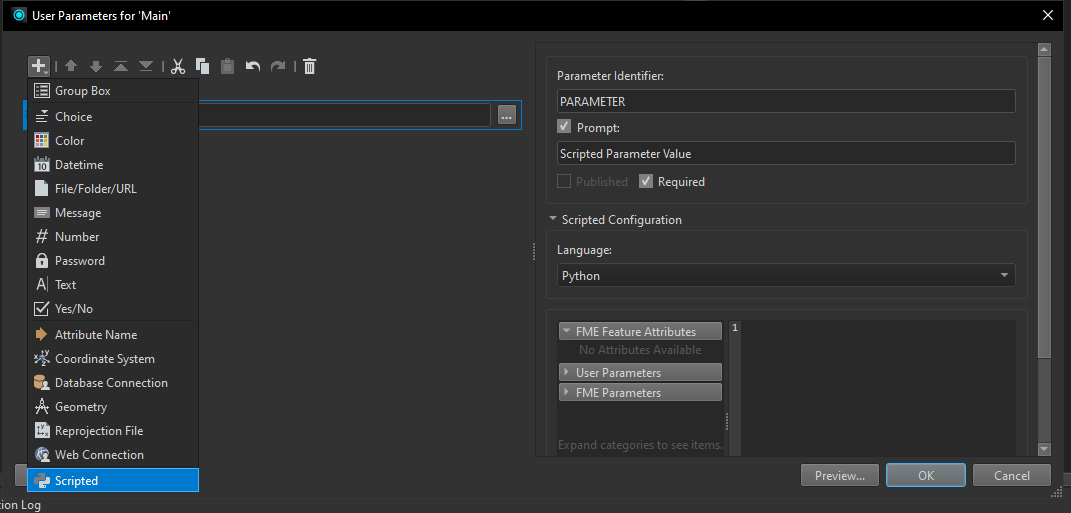
Does anyone know if there's a way to easily load attributes from a simple JSON file to be used as Parameters in an FME workspace (Workbench 2022.2)?
I want to be able to alter the values in the JSON file and have the changes reflected in the FME Parameters, instead of having to manually set each parameter in FME by hand when I want to make a change.
Here's a portion of the JSON file I'm using.
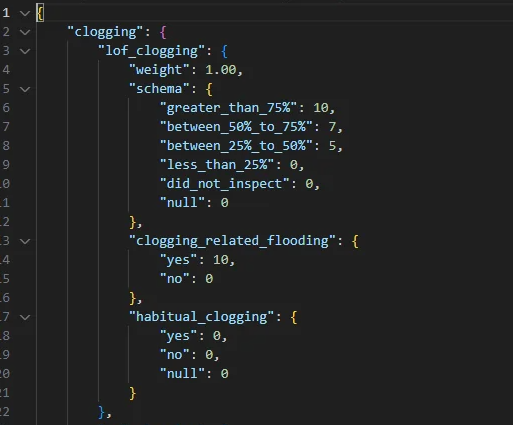
I've tried using the JSONFeature Reader in combination with VariableSetter/VariableReader and MultiVariableSetter/MultiVariableReader to some degree of success. However, it's far from perfect, being quite troublesome to set up and requiring the redefinition of variable names.
I've also attempted to throw the output of the JSONFeature Reader into the attributes of the table I am transforming but only the first row of the dataset receives the attribute values. There may be some way to create new columns for each JSON attribute and fill the new columns with duplicated values from the JSON file. However, that would add about 80+ columns to the table and I think that is not the best way to go about it.
Here's the general way I am using the JSON in a separate Python script
import json
import numpy as np
import pandas as pd
# Load the adjustable schema
new_schema = json.load(r"..\new_scoring_schema.json")
# Load the tranformation dataset
wdf = pd.read_csv(r"..\clean_data_to_transform.csv").fillna(np.nan)
def apply_schema(
df: pd.DataFrame, col: str, ref: dict, weight: float = 1.00, nan_val: int = 0
) -> pd.Series:
wdf = df.copy()
# If the schema contains explicit null value alter np.nan to "null" for map
if "null" in ref:
initial = wdf[f"{col}"].fillna("null")
applied = initial.map(ref)
scored = applied * weight
# If no explicit null value is passed in schema dictionary
# Ignore null values and fill with custom null value (Defaults to 0)
else:
applied = wdf[f"{col}"].map(ref, na_action="ignore")
filled = applied.fillna(nan_val)
scored = filled * weight
return scored
# Consequence Location Flooding
wdf["CL_Flood_Score"] = apply_schema(
df=wdf,
col="flooding_impact",
ref=new_schema["cof_flooding_impact"]["schema"],
weight=new_schema["cof_flooding_impact"]["weight"],
)
I would be fine in the alternate FME process by making each JSON item its own Parameter, instead of how I have the dictionary mapping set up in the Python script. When I used the JSONFeature Reader it flattened the items such that each Key: Value pair was its own Attribute: Value.
Ideally, I would be able to use AttributeManager in combination with the new Parameters to complete my transformations while having a single source document for future value adjustments.
Edit: Also while researching I found this link, which in the extreme case, I might consider attempting to make a Python script to transform my JSON into the appropriate format and insert it where needed. But if there's a simpler way to accomplish this I would be thankful.
https://docs.safe.com/fme/html/FME_JSON_GUI/parameters/
Thank You
Update to Original Post
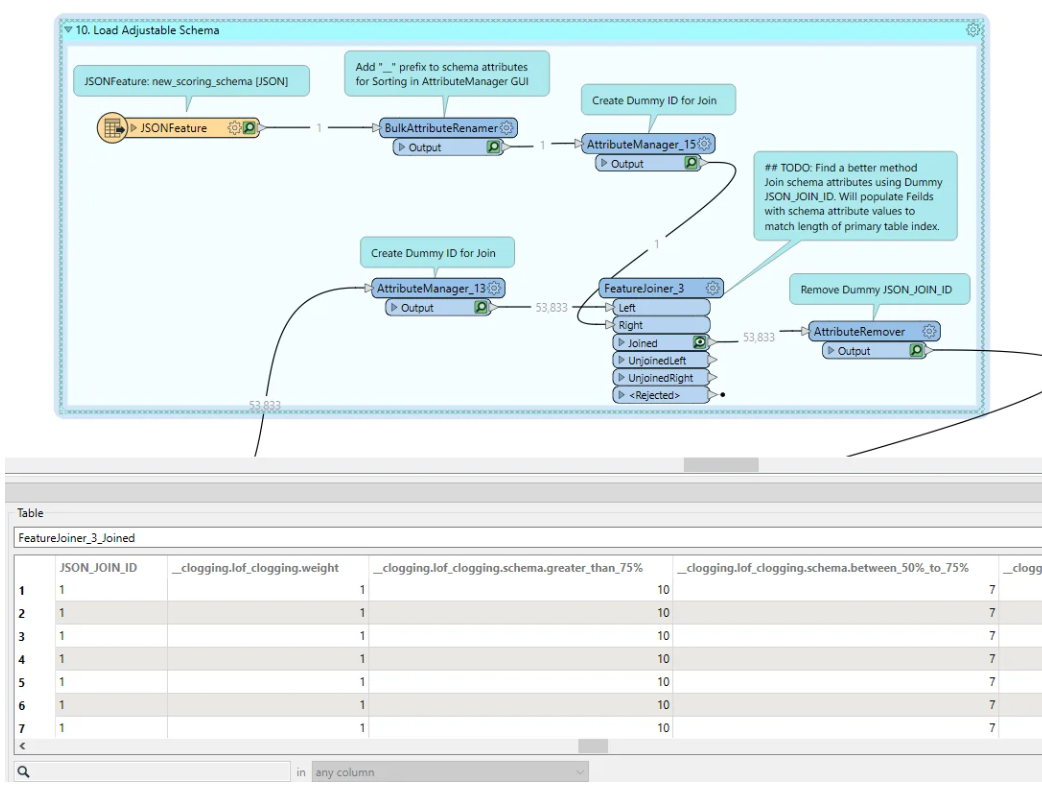
I ended up just creating a fake id to join the values from the JSON to my transformation table as I mentioned previously.
There may be some way to create new columns for each JSON attribute and fill the new columns with duplicated values from the JSON file. However, that would add about 80+ columns to the table and I think that is not the best way to go about it.
Since the data is small I hope it won't have much of an impact on performance adding ~4.2 million data points, most of which are int8 and will be dropped before writing to storage.
Here’s a screen shot of how I joined the JSON attributes to the table.
TL;DR: My goal is to populate Global Variables or FME Workspace Parameters from a JSON document that can be used to do Field Calculations in AttrubuteManager and AttributeValueMapper; such that I could alter the JSON values to modify downstream transformations. Simply joining the attributes in dummy columns to the transformation table adds an unnecessarily large amount of data and leads to decreased performance. Perhaps I am not using them correctly, but my attempts at using the VariableSetter/VariableReader and MultiVariableSetter/MultiVariableReader transformers seem like they would make the Workspace difficult to maintain and modify in the future. Hopefully there is some other way to add a variable to the Global Scope from an input data source that does not require a connection to individual transformers and does not require the redefinition of variable names. Currently I am not aware of any such method.
Thank You

")